Predictive Maintenance - Basics, Strategies, Models
DLG-Expert Report 05/2019

Authors:
- Marc Brandner, m.brandner@cenit.com and Thomas Fritz
CENIT AG, 60528 Frankfurt am Main, Germany
http://www.cenit.de
info@cenit.com
In cooperation with the DLG Working Group Robotics in Food Production.
1. “Predictive Maintenance” Basic Knowledge
Introduction
In the food industry, unforeseen machine breakdowns, drops in performance and quality losses cause high personnel and maintenance costs. The consequences are costly controls of blocked batches and, in the worst case, delivery bottlenecks that lead to a damaged reputation in the trade and among consumers. Stable production performance and sustainable product quality with predictable production costs can only be ensured through efficient and resource-saving production processes. The right maintenance strategy can therefore make a significant contribution to the added value and profitability of a company. However, the choice of the right maintenance model for a production process depends heavily on the complexity of the equipment used, its degree of automation and the possible factors influencing equipment wearout and product quality.

Source: CENIT AG
Traditional maintenance models
In most companies, traditional maintenance models have prevailed, in which known and predefined maintenance activities are scheduled preventively at fixed intervals based on experience and legal requirements, or defects are only reacted to after they have occurred. These classic maintenance models are suitable for simple and largely decoupled manufacturing steps with low degrees of freedom, where their failure has only a minor impact on the entire production process.
However, these classic process models become cost-intensive and inefficient the more factors influence the degree of equipment wearout and product quality and the more automated the lines are. The occurrence of faults can then no longer be estimated on the basis of experience and manual observations alone, which means that “reactive” and “preventive” maintenance quickly reaches its limits here. On the one hand, this results in expensive unscheduled maintenance that
can only be carried out after a malfunction has occurred. And on the other hand, high maintenance costs are also incurred due to maintenance that is carried out too frequently when unscheduled failures must be avoided at all costs for very sensitive units.
Data-driven maintenance models
In order to plan maintenance measures more efficiently and minimize follow-up costs due to unplanned defects, a remedy is provided by data-driven maintenance strategies. A first step is “condition-based” maintenance, in which maintenance measures are carried out depending on the state of wearout or whether defined threshold values are exceeded. In some cases, this can provide transparency, but it presents the challenge of drawing relevant conclusions from huge amounts of data from a wide range of sensors under time constraints.
As a consistent further development of condition-based maintenance, “predictive maintenance” therefore offers a solution that can use modern analysis technologies to predict impending defects from the data in order to be able to take the appropriate countermeasures before an unplanned defect occurs. The methods used are based on the evaluation of process and machine data through automated data analysis in conjunction with predictive models. The methods used are the same as those used to predict the development of stock market prices and storms. Through their targeted use, the following concrete added values can be created:
- Reduction of the frequency of unplanned shutdowns and maintenance work
- Limitation of error causes and recommendation of countermeasures
- Detection of abnormal system conditions based on historical data
- Planning targeted maintenance, only when required
- Reduction of follow-up costs due to increased scrap and consequential damage
Technological vision
Predictive Maintenance is often mentioned in the context of buzzwords such as “Industry 4.0”, “Smart Factory” and “Industrial Internet of Things (IIoT)”. Behind these terms is the vision of a comprehensively interconnected production of autonomous production plants where the production processes can be optimized through data analysis. While
Predictive Maintenance (hereafter abbreviated to “PM”) is cited in the press as a prominent prime example of digitalization in the industry, the roots of the idea lie in the well-known principle of “Total Productive Maintenance” (TPM). This is the continuous improvement of production processes in order to prevent breakdowns and quality problems with all their consequential costs.
While this approach can provide useful metrics (such as “Overall Equipment Effectiveness” = OEE), only data-driven predictive maintenance systems can provide the necessary information at the right time to enable production and maintenance to make decisions that sustainably increase the effectiveness of maintenance and production.
Initial situation in the food industry
In the food industry today, there is a very heterogeneous landscape of production plants which, due to their technology, are only partially equipped with the necessary sensor technology. Even if individual, younger systems are equipped with the appropriate sensors and transmission interfaces, systems – usually from different manufacturers and of different ages – are only networked to a limited extent and controlled by central control levels. Many production and maintenance managers are therefore under the misconception that they cannot benefit from the advantages of predictive maintenance due to the lack of centralized operational data collection. On closer consideration, however, a sufficient number of applications for predictive analysis can also be found in grown production environments.
The following sections are intended to serve as a guideline when starting to implement Predictive Maintenance projects and to illustrate the typical challenges and pitfalls based on practical experience.
2. Analysis of industrial machine data
Analytical methods
In order to detect critical conditions or deviations from standards in production processes, fixed sets of rules are traditionally used in the central control room or on the control panel of a plant to check the measured data. Critical pressure ranges of a pump or insufficient speeds of a turbine are detected by exceeding or falling below fixed predefined threshold values. Although this method can be used to identify problems that occur immediately or have already occurred in the short term, it is not possible to predict the problem hours or days before it occurs. In most cases, early detection is reflected in patterns that are difficult for people to identify by manual inspection and that only become visible when many different data series from sensors and actuators are combined.
In order to use the data generated in the production process to predict defects and wearout behaviour, statistical methods are used in an Exploratory Data Analysis to detect these recurring patterns in the data. These patterns are correlated
in a further step with certain logged events such as past defects, quality problems, plant settings, recipes or processed materials.

Source: CENIT AG
The algorithms used come from the field of “Machine Learning”. They enable training of model to automatically recognize error patterns using so-called “training data”, without having to build a set of rules manually. The decision rules and mathematical functions are learned by the algorithms in a predictive model using the training data. This learning by example is called “supervised learning”.
A model that has been trained once can then be used in everyday production to carry out forecasts and detect gradual wearout automatically and “live” with only a very short time delay. In order for these models to work with the accuracy required in practice, the training data set used must consist of a representative and sufficiently large data set. Only this enables the software to reliably recognize the typical characteristics of the defect patterns and to realistically estimate the time periods of upcoming defects.
Depending on the type of measured variables in a plant, it is therefore not uncommon for several gigabytes of measurement data to have to be processed per machine every day. Depending on the type of production process, it is crucial that these analyses are not only carried out in batches (for example once a day), but as soon as the data has been measured. This type of analysis is called “streaming analytics” because it does not analyse large batches of data (“batch analytics”) all at once, but instead scans a continuous stream of data using the analytical models. Traditional spreadsheets and database systems quickly reach their technical limits here, which is why special Predictive Maintenance systems are usually used for this purpose.
Data sources & data types
A database appropriate to the problem is necessary for the analysis procedures described. An obvious solution is the acquisition and evaluation of classic sensor data on the time axis (time series data), such as pressure, temperature, power consumption or speeds, which are found in almost all production processes. While individual sensors can be considered independently for simple threshold monitoring, a retroactive consideration of the time series without including contextual information would not be very meaningful. A supposedly noticeable temperature rise inside a tank could indicate a malfunction during production, but cloud also be within the normal operating parameters during CIP (“Cleaning In Place”). Only in the context of the sequence control and the process steps of the plant, as well as the combined consideration of several sensor data series, the data volumes do become interpretable at all.

Source: CENIT AG
Although time series data, i.e. time-dependent sequences of sensor measurements, make up the bulk of the data to be analyzed in terms of volume, another important component of the database is so-called “contextual data”. This includes downtimes, error causes, maintenance logs, error messages and information on changes to the product recipe. Often, conclusions and forecasts are only possible when data from several sensors are considered in combination (“sensor fusion”) and these are merged with context data so that a complete picture of the production process emerges from a maintenance perspective (“digital twin”). Even if central operational data collection exists, in most cases further data from different sources must be aggregated and standardised on the timeline so that they can be profitably used for analyses and forecasting models.
Interfaces & protocols
Initiatives to introduce and use Predictive Maintenance rarely start from scratch. Therefore, integration into the technical landscape of the existing production IT (“operational IT”) is essential for the success or failure of the company. The technical challenge is to connect different data sources to a Predictive Maintenance system located in traditional IT.
A central production data acquisition (PDA) or also a line-specific machine data collection (MDC), as well as the ERP system (maintenance and operating logs) are the primary points of contact here.
In order that far-reaching technical changes in system communication do not lead to recurring adaptation efforts in data analysis, it makes sense to use the data already collected at the operational control level or the process control level as far as possible (see figure “Automation pyramid”). In those cases where the data acquisition systems used provide the required data in insufficient density, quality and variety, additional hardware should be used with the help of which the data of individual sensors and actuators can be tapped directly from the automation network. These so-called “IIoT gateways” are an inexpensive retrofit variant that enables subsequent instrumentation of measurement data without the need for complex interventions in existing plants and control systems.
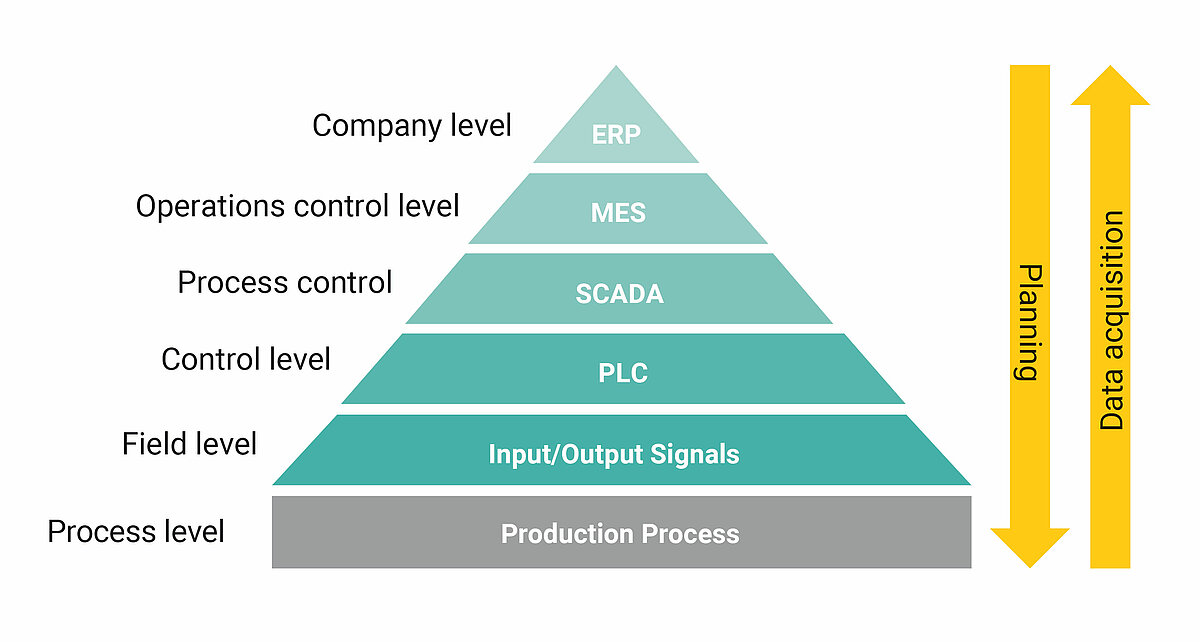
Source: Automation pyramid, designations level 0 to 4 according to IEC 62264
Based on: de.wikipedia.org/wiki/Automatisierungspyramide;
File:Automationpyramid2.svg
The situation is different for newly acquired equipment or production lines. Here, it is possible to benefit from standards at various levels of automation, on the basis of which the subcomponents of a production line speak a “common language” and can therefore be integrated more easily. These standards are of considerable advantage, especially for the collection of operating data, as they allow systems from different manufacturers to provide their operating parameters via a uniform and comprehensible scheme. A uniform specification of the meaning of data structures has been developed in recent years in the form of industry-specific standards such as the “Weihenstephaner Standards” or “PackML” *. In addition, the OPC UA information model for the machine-readable description of production data and for comprehensive process control has become established in the world of automation across all industries. Special retrofit boxes for the DIN rail play only a minor role in production environments at this level, and are only used to make legacy machines fit for connection to standard communication.
3. Implementation of a Pilot Project
Three-phase procedure model
Anyone responsible for production and maintenance in the food industry who is considering the topic of “Predictive Maintenance” is initially faced with a number of legitimate questions, including:
- Which provider or technical platform should I choose?
- How can the risk of a bad investment be reduced?
- When can the first results be expected?
- When will an investment pay for itself?
In the still young history of predictive maintenance projects, a three-phase procedure model has proven itself.

In the first phase, possible use cases in the existing production processes are identified in workshops between maintenance teams, process managers, quality management and automation developers together with a solution partner from the point of view of the various teams in a plant. Ideally, not an entire line but a single, delimited and problematic process step is selected for a pilot project and evaluated on the basis of several professional and technical criteria:
1. Does the application have technical improvement potential?
2. What cost reductions could be achieved with predictive maintenance?
3. From a technical point of view, are the most important factors influencing wear and product quality recorded?
However, in addition to fulfilling these three criteria, it is also important not to be guided primarily by data availability when making a selection (see point 3). Otherwise, a solution using available data results from the pilot, but it does not really solve a serious and visible problem.
The second phase involves an exploratory analysis of historical data, which is recorded and exported once. A live transmission of data is not yet necessary. If the company does not have analysts with the appropriate tools for data analysis, IT service providers can help with the expertise of so-called “data scientists”. The aim of the second phase is to find patterns in the data that can be used as a basis for live analyses based on forecasting models. In this process, the experts from production and maintenance (domain expertise) discuss the results found with the analysts from the service provider (analysis expertise) in several rounds and evaluate their benefits in the context of the production processes. This provides those involved with a manageable complexity and budget with a deeper insight into the process and transparency about the interplay of the various parameters.
“Quick wins” can often be derived from an initial analysis and critical situations can be addressed by making changes to the process control. At the end of such a “proof of concepts”, those responsible for production and maintenance can assess whether valuable insights can already be generated from existing data and whether it is worth investing further in operationalizing a streaming analysis system for Predictive Maintenance. This is where the third phase comes in, in which the implementation and integration of a PM system for selected production steps is technically and economically planned and prepared.
Practical examples
Many potential applications for Predictive Maintenance in the food industry are in the area of packaging or filling of products. Not only are losses at the end of the production process particularly costly, but an unplanned and excessively long downtime of a packaging machine or filling line often means that foodstuffs that are actually in perfect condition have to be destroyed for lack of a buffer. Technically as well, these processes are subject to many influencing factors due to their speed and the large number of moving parts, which is why troubleshooting and optimization in this type of production step is difficult.

An illustrative example of the concrete application of Predictive Maintenance in this area can be found in the brewing industry. When filling beer into glass bottles, bottling plants are used that can fill well over a thousand hectolitres of beer into bottles every hour using the counter pressure filling process. The counter pressure filling prevents the absorption of oxygen in the beverage by equalizing the pressure in the glass bottle with that of the ring bowl, as well as evacuating the bottle, and thus also prevents foaming during the filling process. If the effective pressure during filling or mixing ratios of gases do not match the filling product, bottles may foam over, resulting in low fill levels and oxygen absorption. This usually leads to the rejection of the affected bottles during the final visual inspection of the fill level. Costs caused by product waste, an increased cleaning effort and further consequential damage are the consequence.
One cause of these problems is leakage of the compressed air supply or the seals of the preload valves. These types of leaks are difficult to detect by manual monitoring of the machine parameters, especially in carousel filling machines with multiple filling heads. Another problem is that the internal pressure of bottles is not detected by sensors in many machines for reasons of cost and hygiene. In the present example, an initial exploratory analysis therefore included data from the machine itself, but also from upstream and downstream process steps.
Several predictors were identified that provide particularly high information content for a prediction model. Among others:
- CO2 consumption: Unusual increase in consumption during leakage compared to normal operation
- Bottled product: Measured values vary greatly depending on the bottled product, as different bottling pressures are required for each type of beer (Pilsner, wheat, etc.).
- Current filling rate: Knowledge about the speed of the plant can normalize regular changes in the measured values and classify them as non-critical.
- Various time measurements (including valve switching times): These provide information about seal wearout and leaks in the compressed-air circuit.
Another variable used as a “target variable” in the training of the model is the reject rate in quality control, as this undoubtedly marks a defect state – even independently of human observations. The data measured immediately before these fault conditions are therefore important for the detection of fault patterns. It is important to understand that the individual measurements in isolation do not reveal any significant patterns, as these only emerge when several different measurement series (see “CO2 consumption” and “valve switching times”) are considered in conjunction with contextual data (see “filled product”).

Source: CENIT AG
Based on the model, it is now possible to calculate comprehensible key figures such as a “health score” and to make wearout trends visible via easily interpretable visualizations. If these findings are visible to the staff in charge at all times and made available via alarms, the following added values can be leveraged:
- Cost savings in maintenance and production: Preventing unnecessary waste that is ultimately caused by unrecognised material wear in the filling line.
- Longer warning times: There is enough time for the preparation of maintenance, starting with the compilation of spare parts up to the instruction of the workers.
- Prevention of unplanned outages: Consolidation of already planned repairs reduces downtime
4. Structure of a Predictive Maintenance Solution
System architecture
The development of a system for the acquisition, processing, analysis, storage and presentation of process data can be implemented with reasonable effort thanks to the software systems that have matured in recent years. Figure 8 shows a typical IT architecture for a single plant at a high level.

Source: CENIT AG
IIoT-Gateway – First, it is necessary to transform data from different sources into an analysis format. Only the data necessary for the analyses is retained in the required granularity. In special cases, the analyses can also be carried out entirely on the devices on the shop floor (so-called “edge computing”).
Transmission – In the course of the development in the IoT sector, specialized protocols have emerged for the transmission of sensor data streams through company-internal wide area networks or the Internet. Well-known protocols here are CoAP (“Constrained Application Protocol”) and MQTT (“Message Queue Telemetry Transport”).
Stream Processing & Analytics Engine – As forecasting models usually work with time windows, statistical parameters (mean values, minimum values, maximum values, standard deviations) are determined with the help of stream processing. These values, together with the raw data, are evaluated (“scored”) by the “Analytics Engine” from the prepared forecast models.
Data Lake – In the context of IIoT systems, “data lakes” are special time series databases in which the name-giving time series are stored, if possible, with the original clock rate and accuracy. These allow you to navigate through the data in an exploratory way, even after the fact, without having to wait a long time for reports to be generated.
Feedback – The path back to the shop floor closes the control loop by transmitting the analysis results to the responsible employees via dashboards, notification systems or integration into a ticket system that automatically sends out inspection or maintenance orders.
Process integration
Predictive Maintenance should not only be considered as a stand-alone analysis tool, but must be lived as a process and integrated accordingly into the existing maintenance and production processes. The results of the analysis reported back by the system represent a critical point in the entire process chain and must be delivered to the appropriate
contacts at the right time. The benefit of the most accurate forecasts cannot be leveraged if the necessary responsible parties cannot be informed in time by the system due to technical limitations. Three criteria for the preparation of the results must be met:
- Process-capable visualizations must allow the direct derivation of measures. Examples: Moving planned maintenance forward or reducing a machine cycle.
- Audience-friendly presentation increases the acceptance of the solution, creates trust in the findings and enables transparent decisions. Depending on the recipient, the appropriate visualizations must therefore be created to meet the requirements of the individual teams.
- Easy access to the results through appropriate technical provisioning at several points in the process allows all employees involved in the process to work with consistent data, messages and visualizations. These range from the planning group to the shift supervisor in the control room, and from the machine operator at the plant to the maintenance technician, who is provided with the relevant events via mobile applications and notifications.
These criteria go hand in hand with permanent maintenance and adaptation of the solution. Analysis models must be questioned at regular intervals in order to adapt them to changes in the production process, to correct models or to map new data sources in the analysis.
Operating models
From a technical point of view, the operation of the solution is possible in different variants. For most companies, a cloud-based solution is suitable, in which only a few small components (IIoT gateways) collect data at the factory, while the actual processing and evaluation of the data is operated in a highly available and scalable system in the cloud. The cloud-side operation and the connection of the data sources to the gateways are usually offered by IT service providers as a complete package, so that the company only has to deal with the solution from a technical point of view.
In some cases, operation on the company’s own infrastructure also makes sense, namely when factories are not able to operate applications outside the factory’s own network due to a bad connection to the Internet or company-specific compliancy requirements. In such cases, the introduction of a Predictive Maintenance system works more smoothly and quickly than trying to enfore a cloud-based project.
However, if the option of using infrastructure from a cloud provider such as Amazon Web Services, Microsoft Azure or IBM Cloud is available, smaller investments and rapid technical implementation can offer an advantage over traditional software purchase and operation. This is because the company does not have to build up the necessary compute capacities and operating staff for the analytics applications itself. This option also makes it possible to take care of smaller applications with Predictive Maintenance, where its financial added value through predictive maintenance would be eaten up again by the high operating costs in in-house data centers.
In the rarest of cases, it is profitable to develop an in-house PM system. In most cases, this variant is only suitable for plant manufacturers who want to sell predictive maintenance as a service package together with their plants. Ultimately, the “make or buy” question becomes more of a “rent or buy” question for most food manufacturers. Such “as-a-service” models will determine the market for cloud variants in the future: Food manufacturers do not buy Predictive Maintenance software from service providers, but only the actual analysis service and the associated findings. The necessary IT infrastructure and programmatic adjustments remain the responsibility of the IT and data analysis specialists. This allows the companies themselves to concentrate on optimizing and improving their core processes in food production.
5. Summary
Companies in the food industry usually have an evolved, heterogeneous production landscape. Production and maintenance managers recognize the need to deal with new technologies and Predictive Maintenance, but often lack a concrete starting point or the topic is too complex and gets lost in daily business. The food industry in particular can not only save costs through proactive maintenance, but can also ensure the indispensable ability to serve the market and deliver to consumers.
To get started, a proof-of-concept with a manageable use case and complexity is recommended. This often allows “quick wins” to be generated and the production process to be optimised. Professional IT service providers provide support from the initial analysis and selection of the appropriate operating model to the implementation of a scalable solution and its operation. A step-by-step, pragmatic approach protects against bad investments and ensures success.