Künstliche Intelligenz und Maschinelles Lernen – Wichtige Voraussetzungen und Umfeldbedingungen
DLG-Expertenwissen 04/2022

Autoren:
Dr. Andreas Müller
Physiker und Ingenieur, selbstständiger Spezialist für Lebensmittelsicherheit und -integrität
Andreas.Mueller@stem-in-foodsafety.de
www.stem-in-foodsafety.de
Die Begriffe „Künstliche Intelligenz“ (KI) und „Maschinelles Lernen“ (ML) werden zunehmend auch in der Lebensmittelindustrie inflationär zum Teil auch für Werbezwecke genutzt, ohne dass die Informationsempfänger dabei unterstützt werden zu verstehen, wie KI und ML für die jeweilige Fragestellung eingesetzt werden und insbesondere warum. Sorgen KI und ML als moderne Geheimzutaten für den entscheidenden Wettbewerbsvorteil, obwohl möglicherweise bereits Lösungen existieren? Warum sind diese künstlichen neuronalen Netze besser als vorhandene Erfahrungen und bestehende Lösungen in der Praxis? Hat denn die unternehmensseitig vorliegende Fragestellung überhaupt die Struktur, mit KI und ML bearbeitet zu werden? Bei der Beantwortung dieser Fragen helfen Werbeversprechen meistens nicht. Der vorgegebene Einsatz von KI und ML bleibt oft ein Mysterium. Das vorliegende Expertenwissen möchte aufzeigen, wie KI und ML funktionieren, um ein generelles Verständnis für diese Techniken zu schaffen. Anschließend werden verschiedene Anwendungsbeispiele von ML und KI aufgezeigt und ein Ausblick für eine verbesserte Risikoprävention entlang der Food-Supply-Chain skizziert.
Einführung
Die „Digitalisierung“ von Information schreitet – gerade auch mit der weiteren Verbreitung von Smartphones - sowohl in beruflichen als auch in privaten Lebensbereichen unaufhaltsam voran. Papier wird zunehmend ersetzt durch Bits und Bytes, und mit Hilfe des Internets wird das gesamte Wissen der Menschheit für jeden zugänglich. Mit dem Internet und der freien Verfügbarkeit von Informationen sind Nutzer vor neue Herausforderungen gestellt. Denn in der guten alten Bibliothek aus Papier gibt es Abteilungen mit Sachbüchern und Abteilungen mit Fiktion. Diese Abteilungen sind entsprechend gekennzeichnet und erleichtern die Einordnung von Gelesenem. Im Internet hingegen stehen Wahrheiten, Unwahrheiten, taktische Desinformationen, Hypothesen, Wahn, Meinungen, Fiktionen, Theorien etc. gleichberechtigt und im Zweifel ohne eine hilfreiche Kennzeichnung nebeneinander. Auf welcher Informationsbasis wollen wir zukünftig Entscheidungen treffen?
Mit zunehmender Leistung von Computern und Netzwerken sowie der Geschwindigkeit und Dichte der Informationsverbreitung in Sprache, Wort und Bild werden auch Begriffe wiederentdeckt, die in den 1950er Jahren einmal sehr populär waren und dann über Dekaden im Status der Hibernation verharrten. Zu diesen Begriffen gehören die „Künstliche Intelligenz“ (KI) und das „Maschinelle Lernen“ (ML) sowie Umsetzungsvehikel wie die geheimnisvollen „künstlichen neuronalen Netze“ und „datenstromorientierte Gradientenverfahren“.
Diese reinkarnierten Begriffe erreichen in verschiedenen Modifikationen seit einigen Jahren auch die Lebensmittelindustrie. KI und ML werden oft beworben als moderne Zutat, welche den entscheidenden Wettbewerbsvorteil bringen soll.
Definitionen:
Künstliche Intelligenz(KI), auch artifizielle Intelligenz (AI bzw. A. I.), ist eine übergreifende Bezeichnung für Methoden und Verfahren der praktischen Informatik, insbesondere der Wissensverarbeitung und der wissensbasierten Systeme und in Teilen der Kognitionswissenschaften. Zielsetzungen sind weit gefasst. Die maschinell-komputionale Nachbildung der für den Menschen typischen Fähigkeiten besonders der Intelligenz und der Fähigkeit, Entscheidungen basierend auf Erfahrungen zu treffen, sind die am weitesten gehenden unter dem Aspekt, den Menschen in der Anwendung von KI vollständig zu ersetzen.
Quelle: A. M. Turing: „Computing machinery and intelligence.“ In: „Computers and thought.“ herausgegeben von E. A. Feigenbaum et.al. (New York, 1963).
Maschinelles Lernen (ML) ist ein Gebiet der praktischen Informatik, welches oft in Verbindung mit Künstlicher Intelligenz eingesetzt oder als Teilgebiet von KI gesehen wird. Der Begriff „Maschinelles Lernen“ wurde allerdings unabhängig von der Entwicklung „Künstlicher Intelligenz“ entwickelt und von Arthur L. Samuel im Zusammenhang mit Gewinnstrategien für das Damespiel geprägt. ML zielt darauf ab, Computer zu trainieren und Handeln zu ermöglichen, ohne situationsgenau programmiert zu sein. Maschinelles Lernen ist ein Ansatz zur Datenanalyse, der die Erstellung und Anpassung von Modellen beinhaltet, die es Programmen ermöglichen, durch Erfahrung zu „lernen“. Beim Maschinellen Lernen werden Algorithmen entwickelt, die ihre Modelle dynamisch anpassen, um die Fähigkeit zu Vorhersagen und damit Entscheidungserfolge zu verbessern.
Quelle: A. L. Samuel. „Some Studies in Machine Learning Using the Game of Checkers“. IBM Journal of Research and Development 3:3, 1959, pp. 210–229.
KI und ML – Ein Alltags-Beispiel
Mit der zunehmenden Leistungsfähigkeit von Computern und Computersystemen gewinnen KI und ML zunehmend an Bedeutung, da die technischen Voraussetzungen permanent besser werden. Sie sind aktuell nicht mehr nur ein eher theoretisches und akademisches Themengebiet.
Einer der ersten Einsätze von KI in der zweiten Hälfte der 1950er Jahre war die Buchstaben- und Zahlenerkennung mit Hilfe optischer Sensor-Arrays ähnlich den heutigen Kamerasensoren aber mit weniger Pixeln, nämlich 20x20 anstelle der heute üblichen 6000x4000. 20x20 war die Auflösung, die damals im Labor erreichbar und mit den verfügbaren Rechnertechnologien verarbeitbar war.1
Die Erkennung von Buchstaben und Zahlen funktionierte mit Normschriften und optimalen Kontrastverhältnissen sehr gut. Aber schon kleine Abweichungen von den optimalen Konditionen brachte Fehler, da offenbar das, was Technik an optischen Informationen auswertete und in Buchstaben und Zeilen umschlüsselte, nicht eindeutig war. Menschen werteten diese Fehler aus und variierten den Algorithmus in einer Art und Weise, dass typische Abweichungen vom Optimum mit Zugehörigkeitswahrscheinlichkeiten zu den tatsächlichen Zeichen belegt wurden, was wiederum die Fehlerrate dramatisch reduzierte. Dies war eine Kombination aus „Human Learning“ und einer sehr rudimentären KI.
1 Siehe auch: http://yann.lecun.com/exdb/mnist/index.html . Die Erkennung handgeschriebener Zahlen ist das „Hello World“ der Künstlichen Intelligenz und das „Kapitel 1“, wenn man sich mit neuronalen Netzen beschäftigt
Bilder und optische Abbildungen bzw. deren Restauration eignen sich sehr gut, um die Arbeitsweise von KI und ML zu verstehen. Unscharfe (historische) Fotos, die aufgrund von ungenauen Kameraeinstellungen oder begrenzten technischen Möglichkeiten entstanden sind, sind ein Musterbeispiel für die Anwendung von KI und ML.
Im nachfolgenden Fallbeispiel soll das unscharfe Portrait des Autors verbessert bzw. geschärft werden. Informationen zur Kamera und deren Einstellungen bei der Aufnahme liegen nicht vor. (vgl. Abbildung 1)
Ziel ist die detaillierte Rekonstruktion des Bildes mit fremdem Bildmaterial. D. h. man nutzt das intelligente und passende Zusammenfügen von hochauflösenden Details aus anderen Fotos zu einer Gesamtkollage, welche die gewünschten Details zeigt, ohne den visuellen Zusammenhang zum (unscharfen) Original zu verlieren.
Hierzu werden viele hochaufgelöste, hinsichtlich Schärfe und Detailabbildung optimale Fotos benötigt, die dem Motiv des Originals möglichst gleichen sollen. Diese „Ähnlichkeit“ kann definiert werden über nachfolgende Attribute, welche die Hilfsfotos besitzen müssen:
- Typ des Motivs (hier: Foto, Portrait, frontal)
- Vordergrund-Hintergrund-Helligkeitsverteilung
- Geschlecht
- Kopfbehaarung oder Kopfbedeckung
- Gesichtsbehaarung „Bart“
- Ungefähres Alter
- Brille
- Augenfarbe
- (ggf. weitere)


Das Ergebnis einer solchen Bildsuche könnte dann das folgende Ergebnis bringen (vgl. Abbildung 2, kleine Auswahl aus ca. 612.000 ähnlichen Treffern im Internet, Details aus Datenschutzgründen verfremdet).
Die Qualität der Auswahl kann mit einfachen technischen Mitteln weiter gesteigert werden. Das Gesicht ist für den Menschen das entscheidende Erkennungsmerkmal. Die technische Abbildung der Gesichtszüge (vgl. Abbildung 3) erfolgt durch Verbindungslinien zwischen markanten Punkten, die jedes Gesicht aufweist, die sogenannte Biometrie. Die Fülle an Bildmaterial kann sehr wirkungsvoll weiter eingegrenzt werden, wenn nur Inhalte mit in engen Grenzen übereinstimmenden biometrischen Daten verwendet werden.
Achtung: Bei der Verwendung von Fotos Dritter zur Rekonstruktion von Details sind die juristischen Regelungen des Datenschutzes und der geschützten Persönlichkeitsrechte unbedingt zu beachten. So kann z. B. die verwendete Auswahl hochauflösender Fotos mithilfe von einschlägigen und üblicherweise kostenpflichtigen Bilddatenbanken mit vollständig lizensiertem Bildmateterial erzeugt und streng anonymisiert werden. Nach Verarbeitung und Anwendung werden die Daten dann unwiderruflich gelöscht, und die verwendeten Details für das zu rekonstruierende Foto können nicht mehr zum Ursprungsfoto zurückverfolgt werden. Für das hier gezeigte Beispiel wurde die biometrische Zerlegung ausschließlich für das Autorenfoto verwendet. Eine biometrische Analyse weiterer Fotos erfolgte nicht.
Aufgabe der KI ist es nun, in diesen hochauflösenden Fremdfotos Bereiche zu finden, die geeignet sind, unscharfe Bereiche im Originalfoto mit hochauflösendem Bildmaterial zu substituieren, ohne den Gesamteindruck des Originalfotos zu verändern. Es soll also fremdes Bildmaterial verwendet werden, um eine hohe Auflösung vorzutäuschen. Man kann hierfür ein Raster über die Fotos legen und Bildinhalte vergleichen. Viel geeigneter ist allerdings eine dynamische Einteilung nach biometrischen Feldern und Bereichen mit zahlreichen Kontrastvariationen. Die für die Ergebnisbewertung durch den Menschen wichtigen Augen- und Mundpartien werden hierbei viel feiner geprüft und nachgebildet als z. B. die Stirn, die oberen Teile des Kopfes und die Wangenbereiche, die kaum individuelle Strukturen aufweisen.

Für jeglichen Einsatz von KI und ML ist nun eine wichtige Randbedingung zu schaffen: das Stabilitäts- oder Konvergenzkriterium. Dieses wurde oben schon genannt: „der Gesamteindruck des Fotos soll sich durch die Substitutionen nicht ändern“. Eine maschinenverwertbare Metrik dieser Anforderung könnte beispielsweise lauten:
Vom Originalbild wird durch Mittelung von jeweils 32x32 Pixeln (Helligkeits- und Farbwerte) ein Referenz-„Thumbnail“, also ein in der Auflösung stark reduziertes, kleines Referenzbild erzeugt. Folgendes wird für die KI gefordert:
- Die biometrischen Abstände und deren Verhältnisse dürfen sich nach jeglicher Substitution gegenüber dem Original um maximal 5 % unterscheiden. Weiterhin muss gelten:
- Nach jeglicher Substitution wird vom entstandenen Bild ein temporärer Thumbnail berechnet. Dieser darf sich vom Referenz-Thumbnail um maximal 15 % bei den Kontrastgradienten und um maximal 10 % von deren absoluter Position innerhalb des Thumbnails unterscheiden2. Ansonsten wird die durchgeführte Substitution verworfen.
- Nach 32 erfolgten Einzelsubstitutionen erfolgt eine Bewertung durch den Menschen3.
Anders ausgedrückt: jegliche Verwendung von substituierendem Bildmaterial darf die Umrisse des Originalbildes nicht verändern. Nach 32 in diesem Sinne zulässigen Substitutionen erfolgt eine Bewertung des Gesamtergebnisses durch einen Menschen. Den Bildspeicher in den biometrischen Bereichen nach geeigneten hochauflösenden Partien von Gesichtern zu durchsuchen, diese unter Beachtung der Stabilitätskriterien mit angepassten Helligkeits- und Farbwerten möglichst nahtlos in das (noch) unscharfe Originalbild einzufügen, ist eine programmiertechnisch einfach umzusetzende Aufgabe.
Zu diesem Zeitpunkt sind erste Substitutionen im Originalbild unter Berücksichtigung der Konvergenzkriterien erfolgt. Die KI muss nun „Feedback“ zum Ergebnis erhalten. Hierzu ist eine Ethik zu definieren, die „gut“ und „schlecht“ maschinenverwertbar aufschlüsselt.
In Abbildung 4 sind das Ergebnis des ersten Zyklus von Substitutionen und der dazugehörige Thumbnail dargestellt. Die definierten Stabilitätskriterien sind augenscheinlich eingehalten (Bild-im-Bild): der Thumbnail zeigt unverkennbar den Autor. Die im Originalbild vorgenommenen Substitutionen sind von sehr heterogener Qualität. Während Mund und Nase bereits mit hohem Detailgrad und weitgehend frei von Artefakten dargestellt werden, wirkt der gesamte Augenbereich einschließlich der Brille verheerend und unnatürlich. Der obere Teil des Kopfes sowie der Übergang zum Hals- und Brustbereich sind noch nicht berücksichtigt.
Diese Bewertungen aus der Sicht eines menschlichen Betrachters müssen nun der KI gespiegelt werden. Hierzu wird man den vorgenommenen Änderungen im Mund- und unteren Nasenbereich (identifizierbar durch die entsprechenden biometrischen Feldkombinationen) eine hohe Punktzahl geben, dem Bereich der Ohren eine mittlere und dem Bereich Augen und Augenbrauen eine niedrige Punktzahl4. Hiermit wird in einem ersten Schritt mitgeteilt, welches eine „gute“ und welches eine „schlechte“ Substitution war. Jede einzelne Substitution kann über einen Vorher-nachher-Vergleich (z. B. aufsummierte Kontraste etc.) auch quantifiziert werden, so dass jede durchgeführte Substitution mit einer Änderung und einer Bewertung assoziiert ist.

2 Die gewählten Prozentsätze hängen von der Menge an verfügbaren Bildmaterial für die Substitutionen ab. Je mehr Material zur Verfügung steht, desto strenger können die Grenzen gefasst werden. Prinzipiell sind die Zahlen willkürlich.
3 Die Zahl 32 ist hier willkürlich gewählt. Die Substitutionen sollten für den Menschen erkennbar, unterscheidbar und von der Eignung her differenziert bewertbar sein.
4 Bei einer programmiertechnischen Abbildung als künstliches neuronales Netz würde man die Assoziationen, die zu den Änderungen im Mund- und Nasenbereich geführt haben, verstärken. Entsprechend werden die Assoziationen, die zu den Änderungen im Augenbereich geführt haben, abschwächt. Wir verwenden in dieser Publikation eine Scoring-Methode oder auch Soll-Haben-Methode, also die Vergabe oder der Abzug von Punkten für Veränderungen ähnlich den Bewegungen auf einem Girokonto.
Die KI wird nun in den weiteren Durchläufen die mit „gut“ assoziierten Substitutionen als Basis für die Bewertung weiterer Substitutionen zu verwenden. Für „gut“ befundene Substitutionen werden in ihrer Auswirkung verstärkt, für „schlecht“ befundene Substitutionen werden rückgängig gemacht und mit einer anderen Auswahl ersetzt, welche dann mit „gut“ assoziiert ist. Bildausgangsmaterial ist ja in großer Menge vorhanden. Nach jeweils 32 weiteren Substitutionen erfolgt eine erneute Beurteilung durch den Menschen, bis a) jeder biometrische Bereich mindestens einmal substituiert und bewertet wurde und b) möglichst keine „schlechten“ Substitutionen mehr vorgenommen wurden. Üblicherweise ist dies nach etwa fünf bis zehn Zyklen der Fall. Danach optimiert sich der Prozess eigenständig und benötigt die menschliche Interaktion nicht mehr. Das Training der KI ist abgeschlossen, der Algorithmus läuft von allein, und solange die Stabilitätskriterien erfüllt sind, dürfen sich Substitutionen auch überlagern, d. h. dürfen Substitutionen durch noch bessere Substitutionen ersetzt werden.
Der Algorithmus wird nun, gelenkt vom Training und den „gut“-„schlecht“-Kontrasten, den Bilderspeicher solange nach möglichen das Originalbild verbessernden Bereichen durchsuchen, bis entweder eine maximale Zahl von Durchläufen erreicht ist (bzw. eine maximale festgelegte Rechenzeit) oder die Vorher-nachher-Vergleiche keine signifikante Verbesserung mehr erzielen und stagnieren (statistische Signifikanzanalyse). Hierbei kann es vorkommen, dass der Algorithmus, in Abhängigkeit von der (menschlichen) Konsistenz in der Trainingsphase, mehrere „optimale“ Lösungen findet. Für das gewählte Beispiel des unscharfen Autorenportraits lieferte die KI zwei Lösungen jeweils bestehend aus mehreren 100 Einzelsubstitutionen, die sich fast gleichen. Abbildung 5 zeigt eines der Endergebnisse im Vergleich mit dem (unscharfen) Original.
Das rechte Bild enthält außer Farb- und Helligkeitsverteilungen keine Information mehr aus dem Originalfoto, sondern besteht zu 100% aus künstlich-intelligent zusammengesetzten Fragmenten aus 1000en geeigneter Einzelfotos. Natürlich erkennt der Autor feine Unterschiede zum Original im Spiegel, aber die KI liefert ein erstaunlich gutes Ergebnis, einschließlich unveränderlicher Kennzeichen (Narben), Falten im getragenen Hemd und dem Muster der Krawatte.
Die antrainierte Ausgestaltung des Ethikkorridors lässt sich zusammen mit den Stabilitätskriterien nun nahezu ohne weiteren Trainingsaufwand für jedes Portrait anwenden. Mit den bis hierhin erarbeiteten Informationen kann fast jedes Portrait- oder Gesichts-Foto in überraschender Qualität rekonstruiert werden. Zusätzlicher Trainingsbedarf entsteht für die KI, wenn die Bildstruktur stark von den hier gezeigten abweicht, z. B. bei Bärten oder Brillen mit gefärbten Gläsern, weil diese Einfluss auf die Biometrie nehmen können. Das „Remastering“ alten Foto- und Filmmaterials mittels KI ist inzwischen zu einem eigenen schnell wachsenden Industriezweig geworden.


Das prinzipielle Vorgehen bei der Auswahl von Aufgabenstellungen für den Einsatz von KI und MI sowie die Implementierung derselben ist fast immer dasselbe, so dass sich dieses Verfahren auch anhand von Beispielen aus der erweiterten Lebensmittelindustrie demonstrieren lässt.
Abgrenzung von ML und KI von iterativen Optimierungsverfahren
Zunächst ist es erforderlich, den Einsatz von ML und KI von numerischen und iterativ funktionierenden Optimierungsverfahren abzugrenzen, die mitunter das Label „Künstliche Intelligenz“ tragen, mit dieser aber nichts zu tun haben.
Wie zuvor dargestellt, ist KI sehr gut geeignet, einen Mangel an Informationen intelligent zu kompensieren, indem Muster erkannt und mittels alternativer Informationsquellen zielgerichtet extrapoliert werden. Nahezu allen KI-Anwendungen ist gemeinsam, dass eine mathematisch gut beschreibbare Zielsetzung existieren muss (das Stabilitätskriterium) und dass z. B. über den Prozess des ML eine Ethik vermittelt wurde, die der KI eine Unterscheidung von guten und schlechten Ergebnissen bzw. eine eigenständige Optimierung ermöglicht. In der Praxis finden sich immer wieder beworbene KI-Lösungen für Fragestellungen, die reine Optimierungsaufgaben und damit mathematisch geschlossen lösbar sind. Hierbei wird die Lösung häufig iterativ gefunden, um Anwendungen flexibel zu halten, iterativ ablaufende Algorithmen sind allerdings nicht gleichbedeutend mit KI und folglich konzeptionell völlig anders einzusetzen.
So ist zum Beispiel die Ermittlung von Steigung und Achsenabschnitt einer Ausgleichsgeraden eine sehr einfache Optimierungsaufgabe für einen Effekt, der sich z. B. aus experimentell ermittelten Messwerten ergibt, hinter dem die Theorie einen linearen Zusammenhang postuliert (vgl. Abbildung 6). Wir kennen also bereits die Funktion und haben viel mehr Information als wir für die Definition einer Geraden benötigen, die Fragestellung ist also im mathematischen Sinne überbestimmt. Die Optimierungsaufgabe wird dann so formuliert: „Gesucht wird genau die Ausgleichsgerade, für welche die Summe der Abweichungsquadrate5 der Messpunkte von der Geraden in y-Richtung minimal wird.“. Für die Lösung der Aufgabe berechnet man die Summe als Funktion von Achsenabschnitt und Steigung.
Aus der Schule ist bekannt, dass ein Minimum bedeutet, dass die erste Ableitung der Funktion verschwindet (horizontale Tangente). Es ergibt sich ein lineares Normalgleichungssystem: zwei Gleichungen mit zwei Unbekannten. Dieses ist mit den Methoden der Schulmathematik in einem Schritt unmittelbar lösbar und liefert Achsenabschnitt und Steigung der Ausgleichsgeraden. Die Aufgabenstellung ist hiermit gelöst.
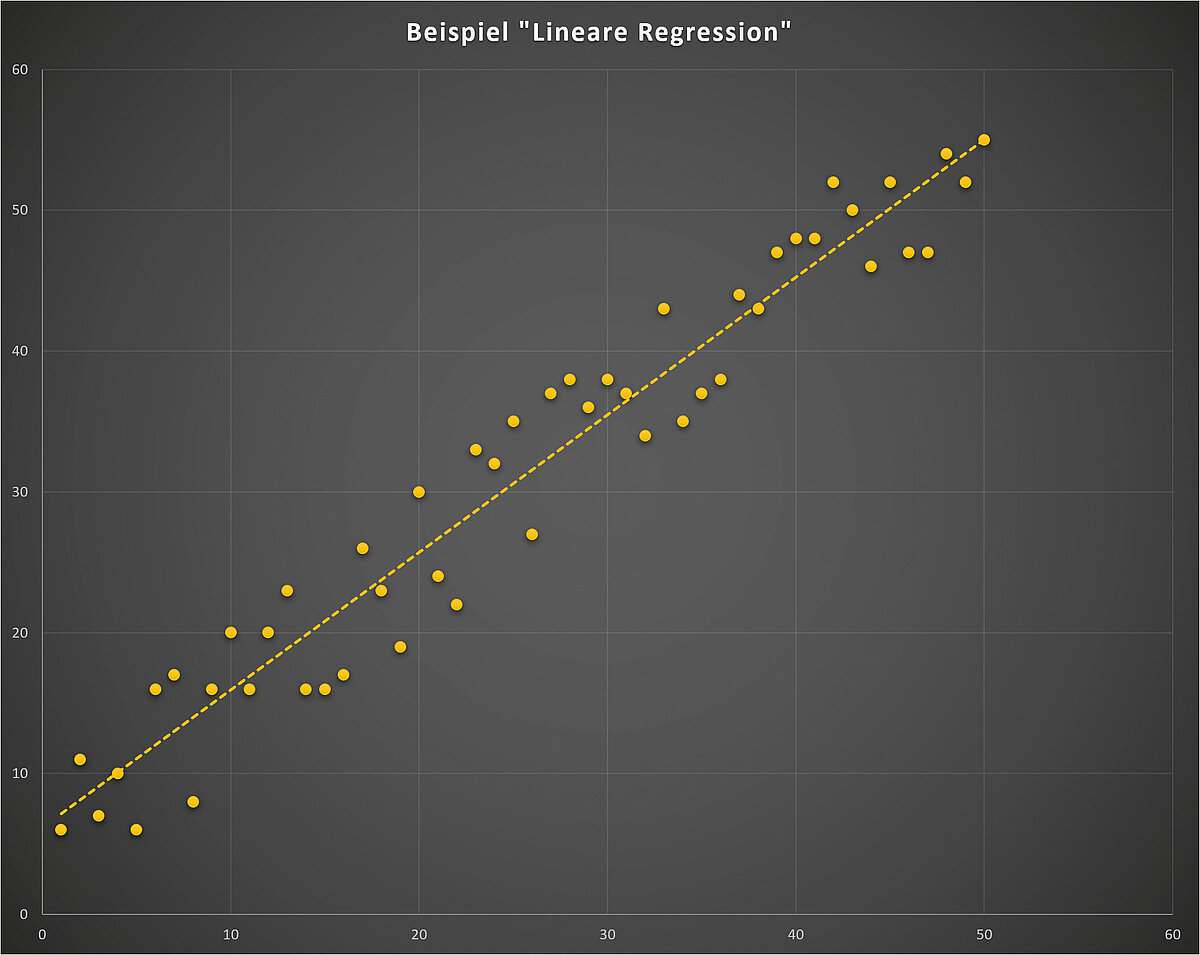
Das mathematische Verfahren für nichtlineare Regressionen ist prinzipiell identisch, allerdings nicht immer mit analytischer Mathematik lösbar. Eine numerische Lösung arbeitet iterativ, indem sie sich ausgehend von Startwerten dem Optimum schrittweise nähert. Bei sehr komplexen Funktionen und Fragestellungen kann dies sehr rechenintensiv sein. Aber der Algorithmus erfüllt die Kriterien für die Verwendung des Begriffs „Künstliche Intelligenz“ dennoch nicht. Denn weder bedarf es einer Trainingsphase für die Algorithmen, noch ist ein Ethikkorridor „gut-schlecht“ als Entscheidungsgrundlage für automatisch generierte Lösungsevolutionen notwendig. Bei allen Optimierungsaufgaben sollte immer zunächst geprüft werden, ob ein klassischer Regressionsansatz gefunden werden kann. Wenn nein, dann liegen möglicherweise Voraussetzungen für den Ansatz von KI zur Lösung der Aufgabenstellung vor.
Im folgenden Kapitel werden Beispiele aus der erweiterten Lebensmittelindustrie aufgeführt, bei denen es zwar um Optimierung geht, bei denen sich aber Randbedingungen ständig ändern, so dass klassische Optimierungsverfahren nicht störungsfrei angewendet werden können.
5 Die Gründe für die Verwendung der „Quadrate der Abweichungen“ liegen in der Wahrscheinlichkeitsrechnung und der Statistik. Bei der Verwendung der Quadrate werden andere interessante Größen zugänglich und konsistent berechenbar wie z. B. die Korrelation der Messpunkte oder der Erfüllungsgrad der Hypothese, dass hier wirklich ein linearer Zusammenhang besteht.
Anwendung von KI in der erweiterten Lebensmittelindustrie
Unter der „erweiterten“ Lebensmittelindustrie wollen wir im Folgenden die Wertschöpfungskette oder Teile hiervon, aber auch unterstützende Prozesse wie Qualitätssicherung, Logistik und den Handel verstehen. Die folgenden Beispiele sind geeignete Beispiele für die Anwendung von KI-Methoden:
- „Sushi on Demand“ oder Herstellung hoch-individualisierter Motiv-Torten oder ähnlicher Konditoreiwaren.
- Probenmanagement in Dienstleistungslaboren im Bereich Lebensmittelsicherheit.
- Versand-Logistik für Online-Lebensmittelbestellungen.
- Initiativen zur Reduktion von Lebensmittelverlusten und -abfällen im Lebensmittel-Einzelhandel.
Vordergründig sind diese vier Beispiele sehr unterschiedlich, weil sie sich thematisch kaum überschneiden. Aus Sicht eines Anwenders von Künstlicher Intelligenz ist die Ähnlichkeit aber gegeben, da die Architektur anwendbarer mathematischer Modelle nahezu identisch ist, auch wenn die Elemente dieser Architektur mit sehr unterschiedlichen Begriffen belegt sind. In Anlehnung an das mathematische Fachgebiet der Graphentheorie kann eine solche mathematische Basis-Architektur schematisch dargestellt werden wie im folgenden Beispiel in Abbildung 7.
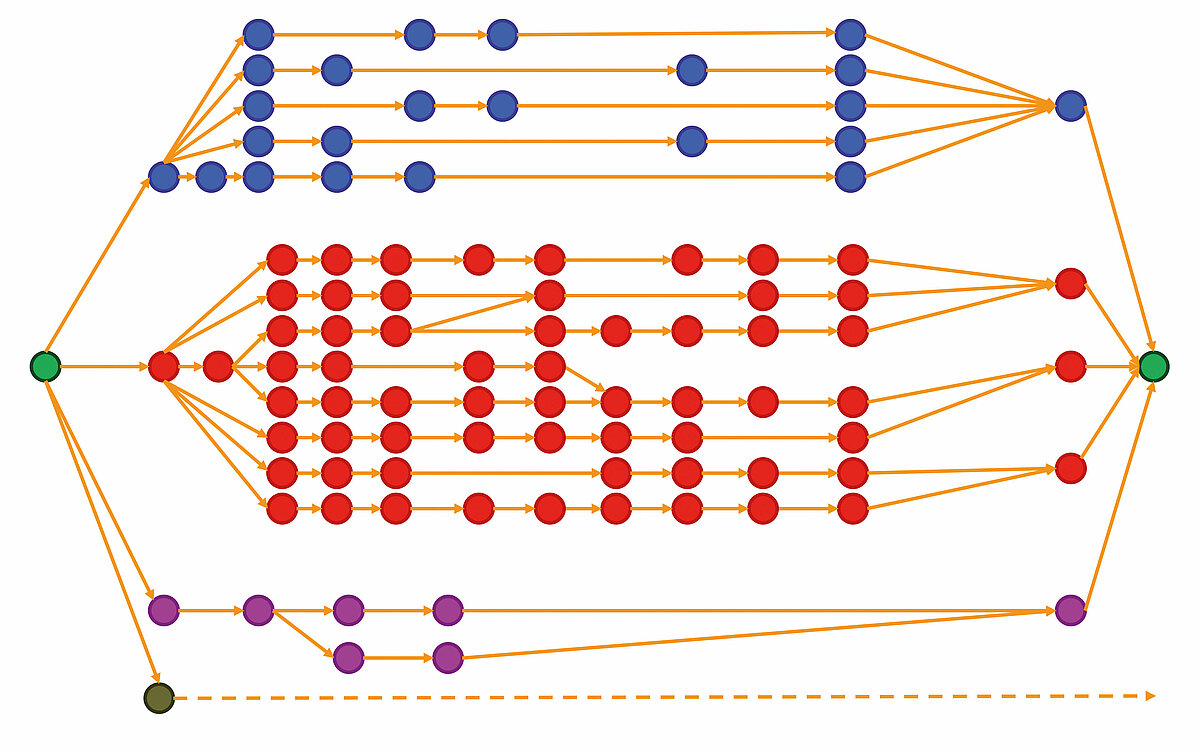
Diese Graphen-Darstellung ist schematisch und kann je nach Fragestellung einfacher oder auch komplexer aussehen. Es werden lediglich zwei Grundelemente benötigt: Zustand (symbolisiert durch einen Kreis O) und Übergang von einem Zustand zum nächsten Zustand (symbolisiert durch einen gelben Pfeil →). Zustände werden gekennzeichnet durch einen Satz von Informationen. Übergänge führen zu einer definierten Veränderung dieser Informationen. Je nach gewünschtem oder verfügbarem Detailgrad lassen sich die Inhalte ein- und ausklappen. Die Struktur ist auf allen Detailebenen selbstähnlich, d. h. die Struktur bleibt gleich, die inhaltliche Ausgestaltung ist variabel.
Ganz links im Graphen haben wir eine Eingabe (grün, hier der Einfachheit halber dargestellt als nur ein Zustand). Ganz rechts im Graphen haben wir die gewünschte und durch den Prozess dazwischen erzeugte Ausgabe (grün). Der Graph ist immer so aufgebaut, dass der Gesamtprozess, von der Eingabe zur Ausgabe zu gelangen, formalisiert und möglichst reproduzierbar abgebildet ist. In der Praxis werden nicht alle Eingaben gleichzeitig und parallel prozessiert werden können. Es ist eine Reihenfolge festzulegen, in der die Eingaben abgearbeitet werden sollen, wobei der Zustrom neuer Eingaben volatil sein kann. Ob die Dimension der Abarbeitung die Zeit ist (Beispiele 1 bis 3: Sushi, Labor, Versand) oder eine Kombination aus Zeit und Verkaufspreis (Beispiel 4: Reduktion von Lebensmittelabfällen), macht für den Einsatz von KI keinen Unterschied. Diese muss nach zwar beschreibbaren aber in der Anwendung dynamischen Kriterien die Reihenfolge der Bearbeitung vorschlagen unter Berücksichtigung der Zielsetzung oder in der von uns verwendeten Terminologie: unter Berücksichtigung der Stabilitätskriterien.
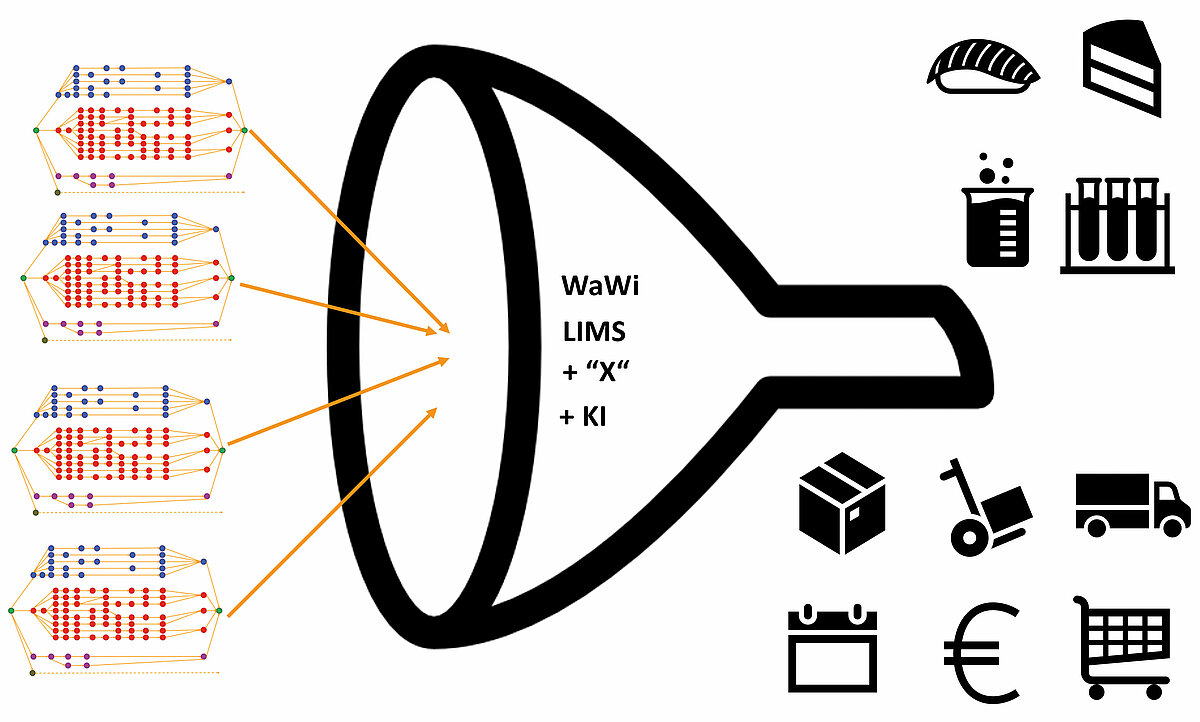
Für die vier Beispiele könnten die jeweiligen Eingaben, Ausgaben sowie die Aufgabenstellungen für die KI und die zugehörigen Stabilitätskriterien wie folgt festgelegt werden:
Beispiel 1: Sushi-on-Demand oder nach Kundenvorgaben gefertigte Motiv-Torten
Eingabe
Kundenbestellung für frisch zubereitete Zusammenstellung mit drei möglichen Prioritäten:
A: sofort (Kunde wartet)
B: dringend (Bestellung mit Abholdatum)
C: planbar (regelmäßige Bestellung für Auslage oder Wiederverkäufer)
Ausgabe
Nach Kundenvorstellung individualisiertes Produkt (Form und Anzahl) abholbereit zum Kundenwunschtermin.
Bedeutung der Graphen-Darstellung
Detaillierte Aufschlüsselung der einzelnen (handwerklichen) Fertigungsschritte bis zum kompilierten Endprodukt. Gestrichelt: Durchreichen von zugekauften Komponenten, die für die Herstellung des Endprodukts nicht verändert werden müssen.
Aufgabenstellung für die KI
Kontinuierliche Überwachung der eingehenden Bestellungen. Erstellung einer dynamischen Arbeitsliste zur optimierten Abarbeitung der Bestellungen unter Einhaltung der Kundenwunschtermine.
Stabilitätskriterium
Alle Bestellungen sollen innerhalb der zur Verfügung stehenden Zeit ausgeführt werden. Vor Bestellungsannahme soll ein Fertigstellungszeitpunkt genannt werden können, wenn der Kundenwunschtermin aus Kapazitätsgründen nicht gehalten werden kann.
Beispiel 2: Probenmanagement in einem Dienstleistungslabor
Eingabe
Kundenauftrag (Probe) mit festgelegtem Prüfumfang für verschiedene Laborbereiche mit drei möglichen Prioritäten:
A: sofort (Freigabeanalytik, produzierte Ware wartet auf Laborergebnis für Verkauf)
B: dringend (heute eingehende Proben werden spätestens morgen begonnen)
C: planbar (Quartalsuntersuchungen, Probenbeschaffung vom Labor organisiert)
Ausgabe
Durchführung der erforderlichen Analysen und Zusammenfassung in einem analytischen Prüfbericht innerhalb des mit dem Kunden vereinbarten Zeitraums.
Bedeutung der Graphen-Darstellung
Detaillierte Aufschlüsselung der einzelnen Prozess-Schritte in verschiedenen Laborbereichen, z. B. Mikrobiologie, Nasschemie, Chromatographie. Kompilierung des zusammenfassenden Prüfberichts. Gestrichelt: Kontextinformation zur Aufgabenstellung, die nicht den Weg in den Prüfbericht findet.
Aufgabenstellung für die KI
Kontinuierliche Überwachung der eingehenden Proben. Erstellung einer dynamischen Arbeitsliste zur optimierten Abarbeitung der Prüfumfänge in den verschiedenen Laborbereichen unter Einhaltung des ersten zugesagten Fertigstellungstermins für alle Proben.
Stabilitätskriterium
Alle Analysen sollen innerhalb der zur Verfügung stehenden Zeit ausgeführt werden.
Beispiel 3: Versandlogistik bei Online-Lebensmittelbestellungen
Eingabe
Kundenbestellung für verschiedene Artikel inkl. Frische, Kühlung und Tiefkühlung, teilweise lagernd mit drei möglichen Prioritäten:
A: sofort (Standard für Lagerware)
B: schnellstmöglich (bestellte Artikel teilweise nicht lagernd, Nachbestellung, konsolidierte Lieferung)
C: planbar (Terminbestellung, Lagerauffüllung für angeschlossene Distributionszentren)
Ausgabe
Vollständige Kommissionierung der Kundenbestellung in geeigneter Transportverpackung und Bereitstellung der versandfertigen Lieferung innerhalb des mit dem Kunden vereinbarten Zeitraums.
Bedeutung der Graphen-Darstellung
Detaillierte Aufschlüsselung der einzelnen Prozess-Schritte zur Kommissionierung der Sendung. Erzeugen von Packlisten. Zusammentragen der beauftragten Artikel aus den unterschiedlichen Lagerbereichen. Vorkommissionierung in geeigneten Transportboxen (ggf. Zusammenstellung mehrerer Collis abhängig von den Transportbedingungen, z. B. Raumtemperatur, Kühlware, TK-Ware). Ermittlung von Maßen und Gewichten und Erstellung der Versandpapiere. Endkommissionierung, d. h. „Boxen schließen“. Gestrichelt: Informationsmaterial und Werbeartikel hinzufügen.
Aufgabenstellung für die KI
Kontinuierliche Überwachung der eingehenden Bestellungen. Erstellung einer dynamischen Arbeitsliste zur optimierten Abarbeitung der Bestellungen unter Einhaltung der Kundenwunschtermine.
Stabilitätskriterium
Alle Kommissionierungen sollen innerhalb der zur Verfügung stehenden Zeit abgeschlossen werden.
Beispiel 4: Reduktion von Lebensmittelabfällen im LEH
Eingabe
Artikelbezogene Bestands- und Wiederbeschaffungsdaten mit Los-bezogenen Informationen zum Mindesthaltbarkeitsdatum (MHD). Aufteilung in drei Fragestellungen:
A: sehr schwierig (lange Lieferzeit, kurzes MHD, volatile Nachfrage)
B: moderat schwierig (kurze Lieferzeit, kurzes MHD, volatile ggf. saisonale Nachfrage)
C: einfach (kurze Lieferzeit, langes MHD, stetige und wenig volatile Nachfrage)
Ausgabe
Dynamische Los-bezogene Preiskorrekturen für Bestandsartikel mit geringem verbleibenden MHD. Frühzeitige Rückführung von Teilmengen bei langfristig antizipierten Überbeständen zwecks Umverteilung oder Weiterverarbeitung in lang haltbare Produkte.
Bedeutung der Graphen-Darstellung
Detaillierte Aufschlüsselung der von Bestandsveränderung durch Abverkauf und Wiederbeschaffung betroffenen Artikel bzw. Warengruppen. Gestrichelt: ggf. Aktionsware oder regional beschaffte, sicher vollständig abzuverkaufende Ware, nicht von der Initiative betroffene Artikelgruppen.
Aufgabenstellung für die KI
Kontinuierliche Überwachung von Beständen und deren Los-bezogenen MHDs. Umschlüsselung in Abverkäufe und Abverkaufs-Prognosen. Erzeugung von Preisreduktions-Vorschlagslisten für Artikel, für die am MHD Restlagerbestand prognostiziert wird.
Stabilitätskriterium
Kein Absatzrückgang regulär bepreister Ware im Vergleich zu retrospektiven Absatzvolumina, d. h. keine Kannibalisierung. Maximaler Abverkauf preisreduzierter Ware mit Zielbestand „Null“ am MHD und Verkaufserlös größer als ein festzulegender Schwellenwert (z. B. Einkaufspreis).
Eine KI-Lösung lässt sich für die Beispiele 1 bis 3 nahezu identisch einführen, lediglich die verwendeten Begriffe müssten ausgetauscht und neu zugeordnet werden. Nachfolgend wird das Procedere am Beispiel 2 des Probenmanagements im Dienstleistungslabor im Detail dargestellt.
Je mehr Informationen im Rahmen der Ausgangssituation zur Verfügung stehen, desto kleiner ist der Trainingsaufwand in der ML-Phase und desto schneller liefert die KI stabile konsistente Lösungen. Fehlen Informationen, verlängert sich die ML-Phase, und ggf. sind keine stabilen Lösungen mehr möglich.
Für das Beispiel des Dienstleistungslabors besteht eine sehr gut geeignete Informationszusammenstellung aus folgenden Elementen:
- Prognose für den erwarteten Zustrom an Proben mit den dazugehörigen Prüfumfängen: Anzahl, Zeitpunkt der physischen Ankunft, Prüfumfang.
- Kundenwunschtermin für die Fertigstellung der Analysen bzw. des Prüfberichts.
- Arbeitsanweisung für jede durchzuführende Methode (d. h. eine Abbildung des individuellen Teilgraphen in der Graphendarstellung).
- Zeitstempel für jeden Prozess-Schritt im Laborinformations-Managementsystem (LIMS).
- Personalbindungszeit und erforderliche Qualifikation für jeden Prozess-Schritt.
- Aufsummierte verfügbare Arbeitszeit je Qualifikation und dazugehörige Arbeitszeiten-Korridore.
- Kapazität und Auslastung der verwendeten Instrumente, Hilfswerkzeuge und Flächen.
- (weitere Informationen, welche eine aktive Produktionssteuerung unterstützen)
Hilfreiche Key-Performance-Indicators (KPIs) sind Bearbeitungszeiten je Laborbereich, Bearbeitungszeit als Prozentsatz der technisch möglichen, minimalen Bearbeitungszeit (immer ≥100%), Auslastungsindizes für Maschinen und verfügbare Laborkräfte, Erfüllungsgrad im Sinne der Ausgabe-Zielsetzung etc.. Mit Hilfe dieser Informationen kann spätestens bei Ankunft der Probe die benötigte Zeit für die Fertigstellung unter idealen Bedingungen berechnet werden. Verweildauern, Bearbeitungszeiten inkl. Transportzeiten im Labor sowie die Nutzungsintensitäten der benötigten Ressourcen in den verschiedenen Laborbereichen sind bekannt. Der Gesamtprozess kann als Graph im obigen Sinne dargestellt werden, damit liegt eine logische und maschinenverwertbare Abbildung des Idealprozesses vor, die den Kern der späteren KI-Steuerung bildet.
Die Implementierung eines KI-gesteuerten dynamischen Arbeitslisten-Vorschlagswerkzeugs folgt inhaltlich den folgenden sechs Schritten, wobei die technische Umsetzung mit dem verwendeten LIMS verknüpft werden kann und auch sollte, um für Nutzer sämtliche Funktionalitäten unspektakulär in einer Nutzeroberfläche integrieren zu können. Die Schritte 1-5 sollten strikt in einer Testumgebung durchgeführt werden. Erst im letzten Schritt erfolgt die Übertragung in oder die Ankopplung an das jeweilige Produktivsystem.
- Es werden Produktionsattribute (z. B. Wegezeiten, Bearbeitungszeiten, Wartezeiten, reservierte Kapazitäten, Rüstzeiten, Automatisierungsoptionen, etc.) sowie Produktionsrestriktionen (z. B. verfügbare Arbeitszeit je Qualifikation) und deren mögliche Kombinationen systematisch variiert, um den Einfluss von Attribut-Restriktions-Kombinationen auf die KPIs zu ermitteln. Dies geschieht anhand der Graphendarstellung, d. h. anhand der logischen Abbildung des Prozesses und hypothetischer Prüfumfänge, die gezielt einen oder mehrere Prozesspfade innerhalb der Graphendarstellung aktivieren. Hinweis: in diesem Schritt sollen die Attribute und Restriktionen gefunden werden, die einen Einfluss auf die KPIs haben. Diese Attribute können je nach Fragestellung auch indirekt und versteckt sein oder aus Kombinationen bestehen.
- Mit dem vollständigen Satz von variierbaren Attributen und Restriktionen wird nun ein hinreichend großer Pool von Stichproben in der Graphendarstellung gegen alle KPIs simuliert. Idealerweise handelt es sich um einen Pool von echten Aufträgen, für welche die tatsächlichen KPIs und Elemente der Graphendarstellung bekannt sind oder rekonstruiert werden können. Diese retrospektive Sicht erlaubt unmittelbar die Bewertung vorgenommener Variationen in den Attributen und Restriktionen: „wie lang wären die Durchlaufzeit und Personalbindungszeiten gewesen, wenn …“. Insbesondere erfolgt für jede dieser virtuellen Auftragsbearbeitungen unter hypothetischen neuen Bedingungen ein Benchmarking im Hinblick auf die Liefertreue d. h. die Einhaltung gegenüber der dem Kunden zugesicherten Bearbeitungszeit. Das Ergebnis ist eine Vorschlagsliste, in welcher die Proben im festen Pool hätten abgearbeitet werden sollen.
- Nun folgt die Festlegung des Ethik-Korridors. Die Trainingsphase oder die Phase des Maschinellen Lernens beginnt. Welche Variationen waren gut, welche waren schlecht? Nach jedem Zyklus (eine Variation, alle Proben im Pool) wird dem System mitgeteilt, ob sich der definierte Satz an KPIs verbessert hat oder nicht. Achtung 1: Man macht immer Aussagen zum vollständigen Satz von KPIs, nicht zu einzelnen ausgewählten KPIs. Zwar kann die Bewertung abgestuft erfolgen (z. B. nach einem Scoring-System), aber alle KPIs sind zu bewerten, und der Satz an KPIs soll nicht verändert werden. Das System benötigt später diese Freiheitsgrade und die Flexibilität. Achtung 2: Die KI soll menschliche Entscheidungskraft emulieren. Hierzu muss eine Bewertung der KPIs nach gut und schlecht vorgenommen werden. Indifferentes Entscheidungsverhalten führt zu Instabilität. Wenn der Mensch unsicher hinsichtlich der Bewertung ist, wird die KI immer weiteren Trainingsbedarf haben, bevor sie stabile Ergebnisse liefert. Im Ergebnis der ML-Phase wird das System bestimmte Variationssystematiken bevorzugen, andere weniger stark gewichten.
- Nun tritt der Mensch als Bewertungsinstanz in den Hintergrund. Das System führt jetzt iterativ (viele) Variationen der Attribute und Restriktionen unter Beachtung der antrainierten gut/schlecht-Kriterien durch. Der Pool an Proben und die retrospektive Betrachtung des Ergebnisses bleiben bestehen. Der Mensch beobachtet das Verhalten der Variationen und deren Auswirkung auf die KPIs. Das System wurde ausreichend trainiert, wenn konvergente Lösungen geliefert werden, d. h. im Mittel stetige Verbesserungen der KPIs bis zu einem Optimum. Ein divergentes Verhalten wäre beispielsweise eine Verschlechterung der KPIs oder realitätsfremde Lösungen, z. B. Aufgabe des Qualifiationsmixes für die Abarbeitung (alle Arbeiten sollen nur von einer Qualifikation durchgeführt werden bei gleichzeitiger Unterlastung aller anderen Qualifikationen). Das System soll sich selbst stabilisieren, sonst reicht das Training noch nicht aus oder die gewählte Stichprobe an Aufträgen ist nicht repräsentativ genug.
- Jetzt erfolgt die Generalprobe. Wir bleiben in der retrospektiven Betrachtungsweise, verabschieden uns aber vom festen Probenpool. Wir erlauben nun eine Dynamisierung entsprechend dem Probeneingang in einem festzulegenden vergangenen Zeitraum (z. B. das vollständige letzte Kalenderjahr). Das System soll nun zu jedem Zeitpunkt eine stabile Lösung liefern, die idealerweise zu jedem Zeitpunkt bessere KPIs geliefert hätte im Vergleich mit den tatsächlich erreichten KPIs. Das Ergebnis ist nun eine KI-generierte Vorschlagsliste für die Reihenfolge der Bearbeitung der Aufträge. Wenn diese Generalprobe über einen längeren Zeitraum (z. B. ein Jahr) retrospektiv gut funktioniert hätte, kann die KI produktiv gehen.
- Übertragung der KI in das Produktivsystem. Verwendung der generierten Arbeitslisten als wesentliches Steuerungswerkzeug für die „Produktion“. Automatisierte Rückmeldung der tatsächlich erreichten KPIs an die KI zur automatisierten Verfeinerung und Anpassung an die Volalität des Tagesgeschäfts. Achtung: Die produktionsnahe Verwendung von KI-Methoden ist unbedingt in einen Qualitäts-Managementprozess der kontinuierlichen Verbesserung einzubetten.
Ein Nebengewinn dieser Vorgehensweise ist, dass Engpässe und Treiber für Ressourcenverschwendung sichtbar werden. Aus den in Punkt 5) erzielten Ergebnissen lassen sich Kapazitätsreserven ableiten. Hieraus kann ein Unternehmen wiederum ein Vorschlagswesen für Prozessverbesserungen ableiten (z. B. Wegezeiten verkürzen, Qualifikationen optimiert einsetzen, verfügbare Zeitkorridore ausnutzen, Automatisierungen einsetzen etc.). Wenn solche Änderungen implementiert werden, muss auch die Graphendarstellung angepasst werden. In der Testumgebung ist dann zu prüfen, ob eine neue Trainingsphase für die KI notwendig wird oder ob die Änderungen des Graphen unmittelbar ins Produktivsystem übergeben werden können. Auch lässt sich die Elastizität des Labors in Krisenfällen simulieren, wie z. B. ein dramatischer Überhang von Priorität A („sofort“) Proben oder temporäre Kapazitätseinschränkungen aufgrund von Krankheit, Umbau, Validierungsarbeiten für neue Geräte etc.
Ausblick: Anwendung von KI bei schwach besetzten Informationsketten
Reduktion von Lebensmittelabfällen im LEH (Skizze)
Nach einer Studie des Thünen-Instituts von 20196 werden in Deutschland jedes Jahr rund 12 Millionen Tonnen Lebensmittel vernichtet. Mehr die Hälfte der Abfälle entsteht beim Endverbraucher. Der LEH selbst ist mit nur 4 % an der Gesamtmenge beteiligt. Unter Berücksichtigung der zugehörigen Wertschöpfungsketten von der Primärproduktion über die Verarbeitung bis hin zum Handel ist das Reduktionspotenzial für Lebensmittelabfälle jedoch erheblich, wie Tabelle 1 zeigt.
Für das Beispiel 4, Reduktion von Lebensmittelabfällen im LEH, ist das bislang beschriebene Verfahren mit angepassten Begriffen zumindest teilweise anzuwenden. Anders als in den Beispielen 1) bis 3) befindet sich hier aber der mittels KI zu optimierende Prozess nicht vollständig im eigenen Unternehmen. Eine Vorverlagerung der Optimierung in Richtung Zulieferindustrie liegt zwar nahe, allerdings sind die Möglichkeiten begrenzt, kleine Mengen beliebig und kurzfristig abzurufen oder Just-In-Time und Customised-Lead-Time Programme zu implementieren. Oft steigen die verbundenen Kosten überproportional an, Verkaufsprognosen sind unsicher, Abfälle entstehen zwar nicht mehr am Ort des Verkaufs aber möglicherweise in vorangehenden Stufen der Lieferkette. Eine gesamtheitliche Lösung unter Einbeziehung der Lieferkette ist prinzipiell anzustreben.
Gleichwohl können KI-Ansätze erhebliche Verbesserungen hinsichtlich der Reduktion von Überschussmengen bringen, sofern Vorlieferanten mit einbezogen werden und zeitgleich die Grundfunktion des Einzelhandels (Zeitüberbrückung, Mengenüberbrückung und Raumüberbrückung) für die Endverbraucher gewahrt bleibt. Eine vollständige Graphendarstellung (vgl. Abbildung 7) für diese Fragestellung wäre aufgrund der Vielzahl von notwendigen Informationsgebern unbeherrschbar komplex. Hinzu kommt eine starke Abhängigkeit des Erfolgs von prognostizierten Daten, insbesondere vom Verbraucherverhalten (Absatzprognosen) und auch von voraussichtlichen Erntemengen für landwirtschaftliche Produkte. Darüber hinaus sind Absatzprognosen für kurze Zeiträume aber auch lateral verteilt d. h. regional aufzustellen, da bei Abweichungen von regionalen Prognosen Waren nicht einfach logistisch (aus Kosten- und auch aus Nachhaltigkeitsgründen) umverteilt werden können.
Für eine ganzheitliche Lösung wären damit sowohl regional spezifische Gegebenheiten angemessen zu berücksichtigen als auch makroökonomische Zusammenhänge und technische Möglichkeiten sowie deren Kosten und Energiebilanzen bei gleichzeitig teilweiser Intransparenz der Informationslage. Dies alles kann nicht durch Computerleistung kompensiert werden, da die Grundlagen zur Aufstellung belastbarer Modelle und Simulationen nicht durchgängig gegeben sind.
Der nun skizzierte Ansatz für eine Teillösung liegt nahe und wird in Variationen auch in Pilotprojekten angewendet. Die Gesamtaufgabe wird in einzelne Stränge in der Graphendarstellung soweit zerlegt, bis die Teilaufgabe vollständig beschrieben und mit Informationen belegt werden. Hierzu wird man eine Warengruppe auswählen, die folgende Eigenschaften erfüllt:
- MHD-Mix im Sortiment. Begrenzte Haltbarkeit für mindestens einen Teil stark nachgefragter Artikel (Achtung: kein Verbrauchsdatum).
- Kontinuierliche zeitliche und regionale Verfügbarkeit.
- Verbraucherseitiger, überregionaler Grundbedarf an Produkten der Warengruppe. Überregional an den Verkaufspunkten erhältlich.
- Mechanismen für Schwankungen in der Nachfrage bekannt und gut zu antizipieren.
- Artikel der Warengruppe wenig prozessiert und zurückführbar auf ein Basisprodukt möglichst aus Urproduktion.
Die aus dieser Sicht geeigneten Warengruppen sind Milch und Molkereiprodukte mit einer großen Spanne von MHD-Intervallen einerseits (von Frischmilch über fermentierte Produkte bis hin zu Kondensmilch und sprühgetrockneten Milchpulvern) und einer saisonal erhöhten Nachfrage einer Sortimentsauswahl andererseits (z. B. Trinkjoghurt, Buttermilch-Produkte aber auch Speiseeis-Sorten mit Milch- oder Sahneanteil 7). Milch und Molkereiprodukte sind überregional in jedem Vollsortiments-Markt verfügbar. Die zugehörigen Wertschöpfungsketten für die Produktion in der Gemeinschaft oder im Inland sind hinreichend transparent.
7 Auch wenn z. B. Milcheis einen Milchgehalt von mindestens 70% aufweisen muss, wird Speiseeis oft als eigene Warengruppe geführt oder z. B. den “Süßwaren” zugeordnet. Die Aufnahme in den KI-Prozess wäre optional aber inhaltlich angeraten.
Die Zielsetzung eines KI-Einsatzes kann nun zwei Strategien (möglicherweise auch gemeinsam) verfolgen: eine verbesserte Planung von Produktionsmengen in Kombination mit der rechtzeitigen Rückführung von Überschüssen vor Ablaufdatum zwecks Weiterverarbeitung in ein weiter prozessiertes Produkt oder Abverkauf überschüssiger Ware. Grundsätzlich kommen hierfür wiederum zwei Mechanismen in Frage: a) Dynamisierung des Mindesthaltbarkeitsdatums und damit eine Verlängerung der zeitlichen Reichweite verkaufbarer Restbestände bei gleichem Preis oder b) eine Preisreduktion bei Annäherung an das fixe Mindesthaltbarkeitsdatum zwecks Schaffung eines zusätzlichen Kaufanreizes für die Verbraucher. Aktive Initiativen arbeiten ausschließlich mit Option b), da eine Dynamisierung des MHD in der Praxis heute noch kaum realisierbar ist.
Für Produkte aus der Warengruppe, für die wegen einer kurzen maximalen Haltbarkeit eine Rückführung zur Weiterverarbeitung nicht möglich ist, kann die Fragestellung „zusätzlicher Kaufanreiz durch Preisabsenkung“ aus KI-Sicht isoliert werden. Hierfür ist artikelbezogen zu ermitteln, ab welcher Resthaltbarkeit die Preisreduktion einsetzen soll und ab welcher Restmenge mit gegebenem MHD. Hierfür sind Prognosen erforderlich. Berücksichtigt werden müssen unter anderem auf regionaler Ebene:
- Retrospektive Verkaufszahlen und ihre Schwankungen in den Dimensionen Menge und Wert aber auch Anzahl der Kaufvorgänge als Indikator für die Kundenanzahl.
- Retrospektive Informationen zu entsorgten Mengen pro Artikel (Referenzgröße für steuernde KPIs).
- Verbleibende Bestände in Lager und Verkaufsregal (MHD-bezogen).
- Sonstige Informationen aus dem Warenbestandsmanagement (z. B. Mengen und Ankunftsdaten nachgelieferter frischer Ware).
Für die kurzfristige Reichweite von Ware mit kurzem MHD müssen die Abverkäufe auch kurzfristig und regional prognostiziert und eine Abhängigkeit der abverkauften Mengen von einer Preisreduktion modelliert werden. Hierfür können u. a. berücksichtigt werden:
- Grad der Preisreduktion.
- Wochenenden, Feier- und Brückentage, Schulferien im Prognosezeitraum.
- Antizipierte Wetterlage im Prognosezeitraum.
- Geplante Massenveranstaltungen im Prognosezeitraum.
Eine KI würde nun Zeiträume für Preisreduktionen und Grad der Preisreduktion variieren und empirisch trainiert werden müssen. „Gut“ wäre eine Abverkaufsrate von Waren kurz vor MHD, die statistisch außerhalb der früheren Schwankungsbreiten der Abverkaufszahlen liegt mit der Folge, dass statistisch signifikant weniger Ware entsorgt werden muss. „Schlecht“ wäre jeder Trend, der darauf hindeutet, dass Kannibalisierung oder Substitutionseffekte auftreten. Das hieße, Verbraucher warten auf die Preisreduktion und reduzieren die gekaufte Menge regulär bepreister Ware. Oder Verbraucher weichen auf andere Produkte aus.
Für Milch und Molkereiprodukte isoliert könnte diese Fragestellung auch als Optimierungsaufgabe, d. h. ohne den Einsatz von KI formuliert werden. Der Nutzen des KI-Einsatzes ergibt sich jedoch, wenn Zusammenhänge auf andere Warengruppen extrapoliert werden und Informationslücken in den Wertschöpfungsketten mittels KI überbrückt werden können.
Sobald die Primärproduktion, Verarbeitungsbetriebe und sonstige Vorlieferenten mit in das Abfallvermeidungsmodell einbezogen werden, ist der Einsatz von KI sogar einfacher durchzuführen als die Gesamtfragestellung in eine Optimierungsaufgabe zu überführen. Aus Platzgründen können hier die möglichen Einsatzfelder der KI nur skizziert werden.
Einsatzfelder KI im Bereich Primärproduktion:
Vermeidung von Überproduktion
- Flexibilisierung von Produktionsmengen – dynamische an Nachfrage angepasste Substituierung.
- Bedarfsprognosen langfristig (Grundbedarf, Trends, positiv besetzte „Issues“, gesetzliche Regelungen).
- Bedarfsprognosen mittelfristig (Wetter, Veranstaltungen, Wettbewerbssituation, Aktionen).
- Zerlegung von Produktionsfaktoren in extrinsische (Wetter, geogene Faktoren, Schädlinge, gesetzliche Regelungen) und intrinsische Beiträge (Region, Technik, Qualifikation, Spielraum für alternative Produkte).
Einsatzfelder KI im Bereich Verarbeitung:
Vermeidung von Überproduktion
- Flexibilisierung des Produktspektrums – Verteilung von Primärrohstoffen auf Waren verschiedener MHD-Klassen.
- Dynamische Prognosen für Bedarfe und Absatzmengen je belieferter Region.
- Rückkopplung der Absatzprognosen in die Produktionsmengensteuerung je MHD-Klasse.
- Rückkopplung der Absatzprognosen in die Lagermengenplanung je MHD-Klasse.
- Optimierung der Verwertung retournierter Ware.
Einsatzfelder KI im Bereich Handel (ohne Verkaufspreisanpassung):
Verbesserung der Zuverlässigkeit von Absatzprognosen
- Mengenprognosen je Artikel im Rhythmus der regulären Wiederbeschaffung.
- Regionale Mengenprognosen je Artikel dynamisch unter Berücksichtigung von Feiertagen, Ferien, Veranstaltungen, Wetter.
- Rückkoppelung der Informationen rückwärts in die Wertschöpfungskette hinein.
Zum Thema KI-Einsatz zur Reduktion von Lebensmittelabfällen in der Wertschöpfungskette gibt es laufende Pilotprojekte, die auch von offizieller Seite gefördert werden.
Ausblick: Anwendung von KI in der Risikoprävention für Lebensmittel
Im Bereich der Risikoprävention und der frühen Warnung vor möglichen Risiken über mehrere Stufen einer Wertschöpfungskette hinweg ist der Einsatz von ML und KI ebenfalls denkbar. Erste konsistente Modellierungen existieren seit Anfang 2022, sind aber bislang nicht veröffentlicht. Am Beispiel eines stark nachgefragten Massenprodukts soll hier die Vorgehensweise erläutert und der Einsatz von KI motiviert werden.
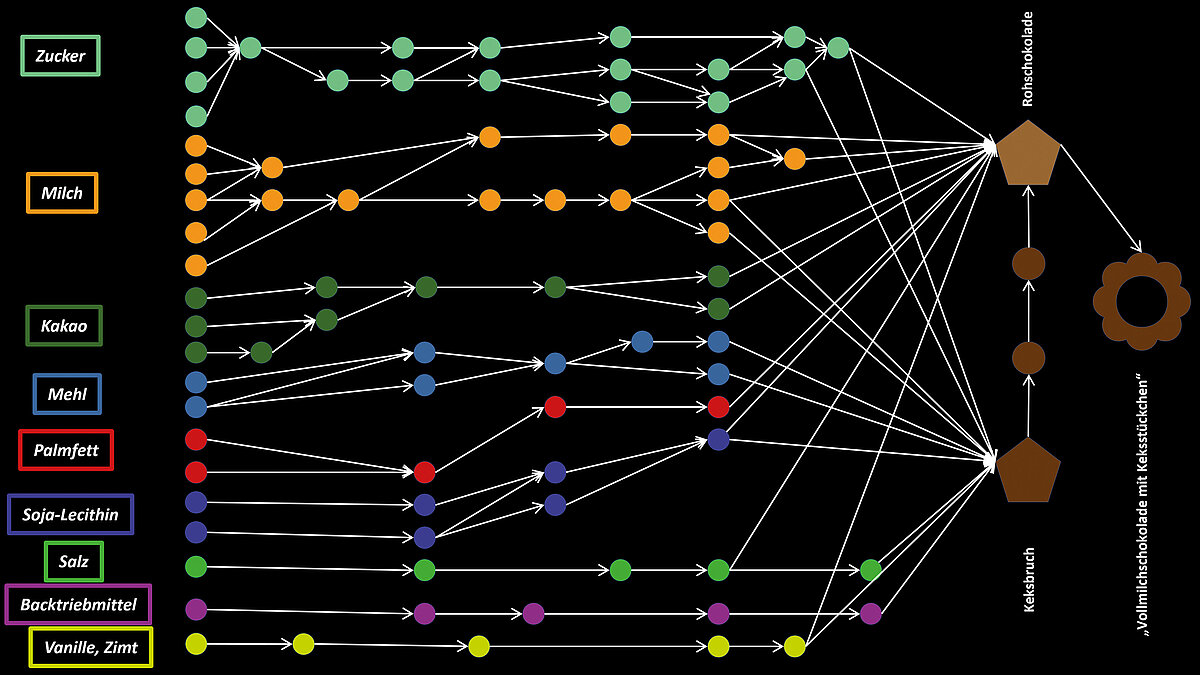
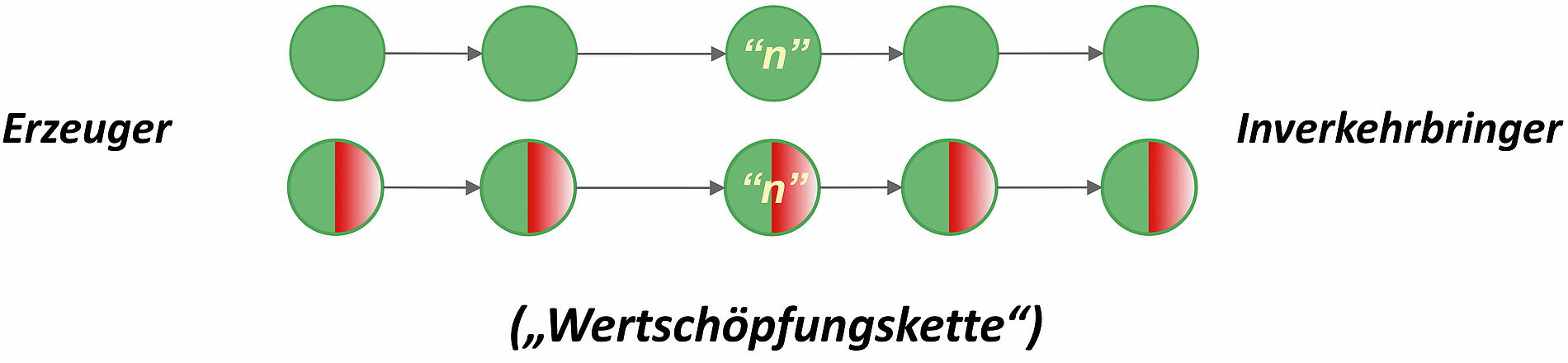
Das Beispielprodukt ist eine fiktive monolithische Schokolade mit Keksbruch „Vollmilchschokolade mit Keksstückchen“.In der nun schon mehrfach verwendeten Graphendarstellung könnte eine stark vereinfachte internationale Wertschöpfungskette wie in Abbildung 9 dargestellt aussehen.
Aus den primären Zutaten (links) wird über viele Prozessschritte (Pfeile), Zwischenstufen und Veredelungen (Kreise) schließlich das Endprodukt (rechts), wie es in den Handel gelangt. Die Transparenz der Wertschöpfungskette für den Hersteller des Endprodukts nimmt in Richtung der Primärzutaten schnell ab, und die verfügbaren Informationen werden immer allgemeiner und wenig spezifisch. Früh in der Wertschöpfungskette auftretende Havarien müssen sich oft erst über mehrere Schritte auswirken, bevor sie erkannt werden und abgefangen werden können. Mitunter finden diese Auswirkungen auch den Weg bis in das Endprodukt oder die Stufe davor. In einem solchen Fall werden mit erheblichen Aufwänden Ursachenanalyse und Schadensaufklärung betrieben. Nicht konforme Ware muss u.U. vernichtet werden.
Die Fragen für einen KI-Ansatz sind nun:
- a) Lässt sich die Wertschöpfungskette mit Blick auf eine Risikoprävention geeignet modellieren?
- b) Sind Informationen vorhanden, die als Stütz- oder Referenzpunkte für die Modellierung dienen könnten?
- c) Lassen sich aufgeklärte Risikoauswirkungen aus der Vergangenheit nutzen, ein unerkanntes Weiterreichen von Risiken über mehrere Stufen der Wertschöpfung zu verhindern?
Zur Beantwortung der Fragen müssen wir die Elemente in der Graphendarstellung geeignet mit Bedeutungen und Informationen belegen.
Wir beginnen mit den Kreisen (vgl. Abbildung 10). Diese bezeichnen Zustände, in dem sich das Produkt in dieser Stufe der Wertschöpfung befindet. Passende Begrifflichkeiten wären: fermentiert, geschält, vermischt, entölt, gebleicht, verpackt, gelagert, usw. Jedem Zustand wird ein Risikoprofil zugeordnet. Dies ist in der Regel ein Vektor, dessen Komponenten aus analytisch zugänglichen, messbaren Größen bestehen. Es bieten sich an die wertgebenden und die wertmindernden Eigenschaften dargestellt als analytische Parameter: z. B. Proteingehalt, Fettgehalt, Theobromingehalt, Cadmiumgehalt, Belastung mit Schimmel, Belastung mit Ochratoxin-A und weitere.

Jeder Pfeil bezeichnet eine Verarbeitung, welche das jeweilige Produkt von einem Zustand in den nächsten Zustand überführt (vgl. Abbildung 11). Passende Begrifflichkeiten wären: ernten, schälen, lagern, mahlen, mischen, erhitzen, transportieren, färben usw. Mathematisch gesehen wäre der Pfeil ein Operator, der einen Vektor in den folgenden Vektor überführt. Eine Steril-Erhitzung würde z. B. eine Mikrobiologie abtöten können (Operator „Null“) aber einen Gehalt an Schimmelpilzgiften nicht verändern (Operator „Eins“).
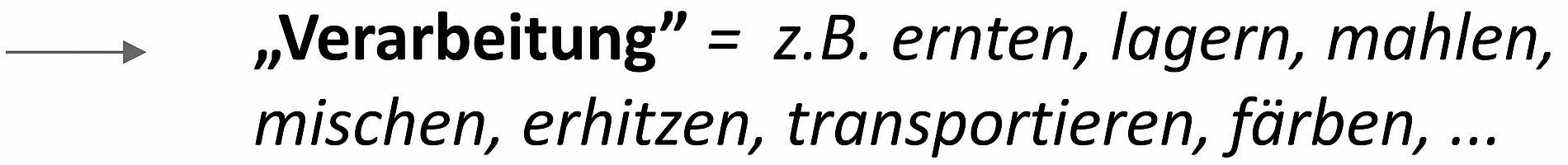
Es bleiben zwei Herausforderungen:
Messdaten liegen bei weitem nicht für alle Zustände vor und häufig auch noch nicht durchgängig entlang der Wertschöpfungskette. Man könnte Zustände, für die keine Messdaten vorliegen, näherungsweise im Rahmen von Modellierungen berechnen und zu einem Teilaspekt des KI-Einsatzes machen. Abgekoppelt von der Frage der Qualität von Daten kann aber die durchgängige Verwendung von BLOCKCHAINs einen wesentlichen Technologiesprung bedeuten und den Einsatz von KI in der Prävention ermöglichen und stimulieren.
Die zweite Herausforderung ist die konkrete mathematische Umschreibung der Transformationsoperatoren (Pfeile). Als Frage formuliert: wie verändern sich meine laboranalytischen Parameter durch den Verarbeitungsschritt, den Transport, die Lagerung? Die Beantwortung der Frage ist nicht trivial und benötigt lebensmitteltechnologisches Tiefenverständnis. Vorstudien zeigen allerdings, dass von rund 2.000 möglichen Operatoren8 in der Praxis nur knapp 300 regelmäßig angewendet werden, was die Komplexität in diesem Bereich erheblich reduziert.
Die KI wird nun auf eine Modellierung der gesamten Wertschöpfungskette – soweit bekannt oder rekonstruierbar – abstellen und Auswirkungen von Störungen in frühen Stadien der Wertschöpfung auf das Endprodukt simulieren und Indikatoren in Form von erwarteten Änderungen der Messergebnisse sichtbar machen, anhand derer ein Risiko ausgewiesen werden kann. Als Stabilitätskriterium gelten die vorhandenen realen Messdaten, die bei jeder Modellierung sicher reproduziert werden müssen und die als Stützstellen für den Algorithmus dienen.
8 Kenntnisstand Juni 2022.
Der Ethikkorridor wird geschaffen mit Hilfe der Rekonstruktion bekannter und aufgeklärter Mängel und Auswirkungen von gut beschriebenen Umständen, die zu einem Risiko geführt haben. Eine erfolgreiche Rekonstruktion ist „gut“. Unrealistische oder „panische9“ Modellierungsergebnisse sind „schlecht“.
Haben sich die Ergebnisse zuverlässig stabilisiert, können die gefundenen Kriterien und Verfahren auf andere Produkte angewendet werden. Hier wird die KI nach ähnlichen Mustern in der Risikofortpflanzung suchen, was anhand der bekannten Zustandsvektoren und Verarbeitungsoperatoren lediglich eine Fleißaufgabe ist und beim Nachtraining der KI als Nebenprodukt abfällt. So konnte in Testmodellierungen gezeigt werden, dass der aus der Vergangenheit bekannte Fall von „Noroviren in TK-Erdbeeren“ einem fast identischen Mechanismus folgte wie der einige Jahre später auftretende Fall „Hepatitis-Viren in Datteln“. In dieser retrospektiven Sicht, hätte der zweite Fall antizipiert und mit sehr frühzeitigen Gegenmaßnahmen belegt werden können.
Die mathematische Abbildung ist sehr klar und arbeitet mit etablierten und seit langem bekannten Techniken. Man nennt dies statisch übersichtlich. Die algorithmische Umsetzung einer solchen Präventionsanalyse auf Basis von KI-Techniken ist allerdings anspruchsvoll, weil die notwendige Informationsmatrix sehr schwach mit Stützstellen besetzt ist und bei genauer Betrachtung die Wertschöpfungsketten eine enorme Menge von Zuständen und Verarbeitungen aufweisen. Für den Menschen sind die Wege und Zwischenresultate der KI-Modellierung nicht mehr zu verstehen oder nachzuvollziehen. Der Mensch konzentriert seine intellektuelle Leistung auf die Stabilität und Konvergenz und die Definition des Ethikkorridors. Im Betrieb sind die KI-Systeme in dieser Größenordnung dynamisch unübersichtlich.
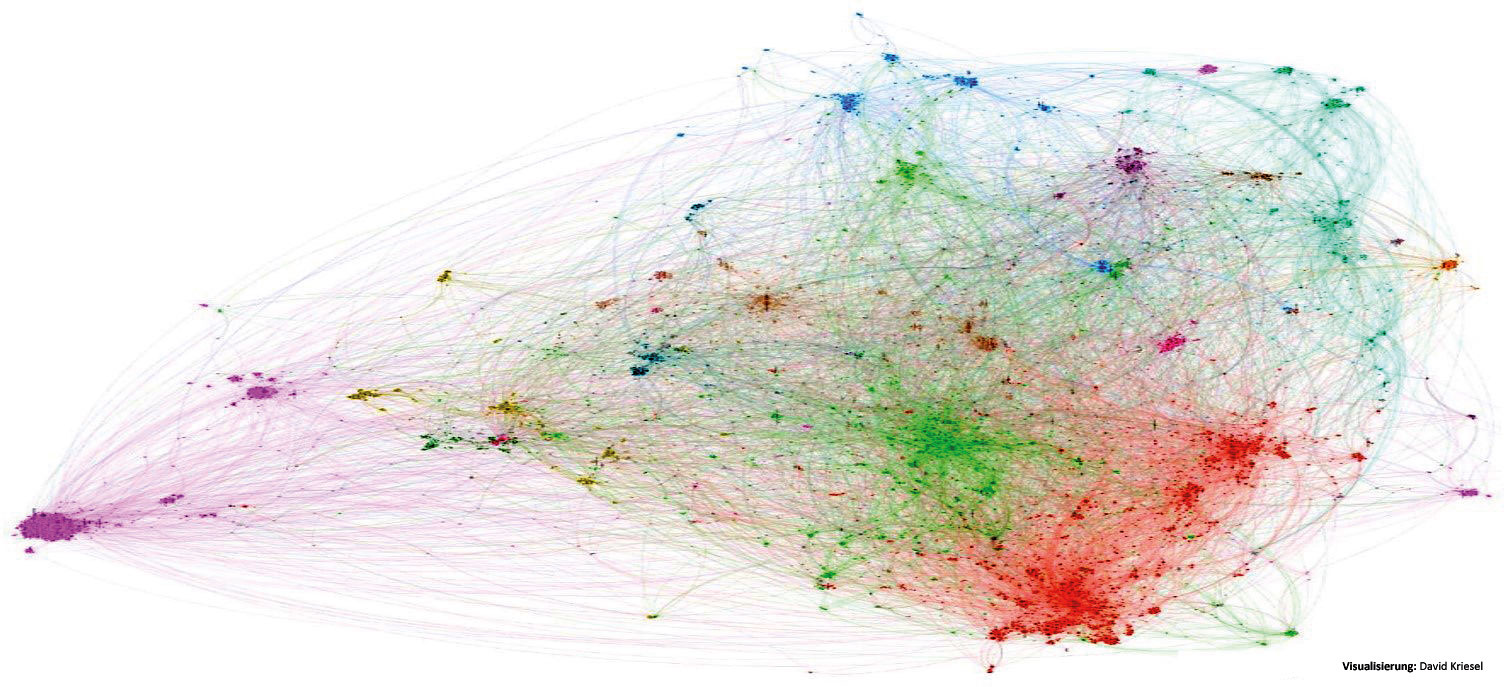
Bei einer Herstellung der Beispielschokolade in Deutschland kann allein der Zucker aus ca. 140 Ländern mit einer zum Teil hochfragmentierten Erzeugerstruktur stammen 10. Führt man eine solche Detailaufstellung für alle genannten Grundzutaten durch, erhält man ca. 90.000 Zustände und Verarbeitungen bzw. Übergänge. Eine realistische Graphendarstellung für die Vollmilchschokolade mit Keksstückchen sähe dann aus wie in Abbildung 13.
Programmiertechnisch sind hier viele flankierende Techniken einzusetzen, um Rechenzeit und Speicherbedarf in Grenzen zu halten und damit nachgelagert auch den Energiebedarf einer solchen Modellierung. Diesen Anspruch auf effiziente Ressourcennutzung teilt die KI mit Anwendung in der Risikoprävention übrigens mit der technischen Realisierung einer BLOCKCHAIN.
9 Da die Belegung der einzelnen Elemente der Wertschöpfungskette mit geeigneten Informationen sehr schwach ist, d. h. viele Informationen
nicht vorliegen und intrapoliert werden müssen, kommt es zu Beginn der Trainingsphase allein aus Stabilitätsgründen der numerischen Verfahren
immer wieder zu Divergenzen. Kein noch so verheerendes Risiko erreicht das Endprodukt oder – viel häufiger – jede noch so kleine
Störung schaukelt sich „panisch“ zu einem maximalen Risiko für das Endprodukt hoch. Im Sinne des Ethikkorridors sind diese Lösungen
„schlecht“.
10 Quelle: Dr. Jörg Klinkmann (Storck), Food Safety Congress 2017 in Berlin.
Zusammenfassung
Mit der in den letzten zwei Jahrzehnten enorm verbesserten Leistungsfähigkeit erschwinglicher Computer erfährt die Künstliche Intelligenz eine Renaissance. Am intuitiv zu begreifenden Beispiel der Restauration von Fotos wurden die elementaren Schritte zur systematischen Implementierung von KI-Methoden illustriert und die Abgrenzung zu iterativ funktionierenden Optimierungsverfahren aufgezeigt. Hiermit soll den Lesern ein Werkzeug an die Hand gegeben werden, Fragestellungen im eigenen Unternehmen auch unter dem Blickwinkel der KI zu bewerten. Dem gleichen prinzipiellen Muster folgend lässt sich die nun „demystifizierte“ KI zur Lösung sehr unterschiedlicher Fragestellungen im Bereich der Lebensmittelindustrie erfolgreich einsetzen.
Der Bereich der vorausschauenden Risikoprävention auf der Basis KI-gestützter Modellierungen besitzt großes Potential, nicht nur Risiken abzuwehren, sondern auch als Werkzeug zu dienen, um die Weiterverarbeitung mangelhafter Waren zu verhindern, was aus Nachhaltigkeitsaspekten erstrebenswerter ist als ein Sortieren von guter und mangelhafter Ware. Die Beschaffung glaubwürdiger umfassender Detailinformationen tritt zunehmend in den Mittelpunkt, wofür sich die BLOCKCHAIN-Technologie als exzellentes Vehikel zur Schaffung der Datentransparenz etablieren kann. Die technische Umsetzung sehr komplexer Fragestellungen, die zwar statisch übersichtlich ist, sich im Betrieb aber komplex darstellt, erfordert hohe fachliche Ansprüche an die Fähigkeiten der Entwickler und eine Routine, mit der Techniken aus dem Big-Data-Umfeld angewendet werden können. Das Potenzial für Sicherheitsgewinne und verbesserte Nachhaltigkeit in der Lebensmittelindustrie ist enorm. Wenngleich sich aktuell viele existierende Ansätze noch im Forschungs- und Entwicklungsstadium befinden, ist der Weg zum erfolgreichen Einsatz und zur Erlangung des Vertrauens der Anwender in diese neue alte Technologie bereits bereitet und eine breite Umsetzung in naher Zukunft wahrscheinlich.
Kontakt
Simone Schiller • Geschäftsführerin DLG-Fachzentrum Lebensmittel • Tel: +49(0)69/24 788-390 • S.Schiller@DLG.org